 pkgonan
pkgonan
주제
- Distributed Cache로 Hibernate Second Level Cache를 적용하여 성능 튜닝하기 - 이론편
목적
- 성능
- 확장성
- DB I/O 감소
배경
- 신규 개발한, 쿠폰 플랫폼은 JPA 구현체 Hibernate를 사용합니다.
- 설계 시 도메인을 작은 단위의 도메인으로 쪼개 설계, 구조적으로 각 도메인은 확장성과 간결함의 장점을 얻을 수 있습니다.
- 단점으로는 여러 도메인으로 쪼개, 상황에 따라 쿼리가 더 많이 발생 가능합니다.
- 이를 보완하여,
DB I/O와 성능을 개선하기 위해 Second Level Cache를 적용하게 되었습니다. - 특히, 쿠폰 도메인은 도메인 특성상 조회/수정의 비율이 조회가 압도적으로 많아, Second Level Cache에 적합합니다.
Why Distributed Cache ?
- 다수의 서비스가 들어오는
플랫폼이기에 성능 뿐만 아니라 확장성까지도 함께 고려해야 합니다. - 따라서, Cache 구현체 및 동작 방식을 확장 가능한 Distributed Cache 방식으로 선택하게 되었습니다.
Why Hazelcast ?
성능을 끌어올리기 위해 Near Cache 기능이 필요하였고, 이를 지원하는 IMDG 기술이 필요하였습니다.Invalidation Message Propagation 기능을 지원하는 Near Cache(Client Side Cache)를 사용하면, Network I/O를 줄여 성능을 극대화 할 수 있습니다.- Redis는 Redis Client 중, Redisson에서만 Near Cache를 제공하지만 유료로 제공됩니다.
- 이에 따라, IMDG 제품 중, 기존에 분석했던 Cache 구현체 별 적합성 분석을 참고하여, NONSTRICT_READ_WRITE 전략을 지원하는 Hazelcast를 Distributed Cache 구현체로 선택하게 되었습니다.
Hazelcast Data Partitioning (Sharding)
- Hazelcast에서의 Shard는 Partition입니다. (Hazelcast 공식 문서 참조)
- 기본적으로 271개의 파티션이 생성되며, Entry key의 Hash 값과 Partition 개수의 Modulo 연산에 의해 파티션 ID가 선택됩니다.
Distributed Cache로서 확장성을 제공하는 방법은 Data Partitioning입니다.- Cache Cluster의 Member가 증가/감소됨에 따라 Partition이 Rebalancing되어 데이터가 분산됩니다.
따라서, 데이터의 분산으로 인한 확장성을 제공하며, 나아가 다수의 컴퓨팅 자원을 활용한 분산 처리가 가능합니다.
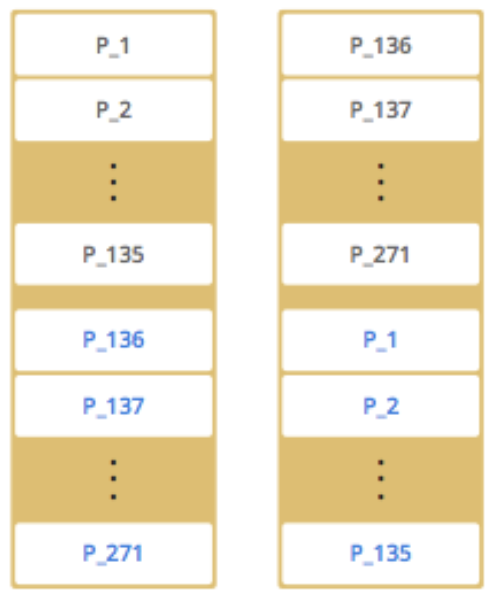
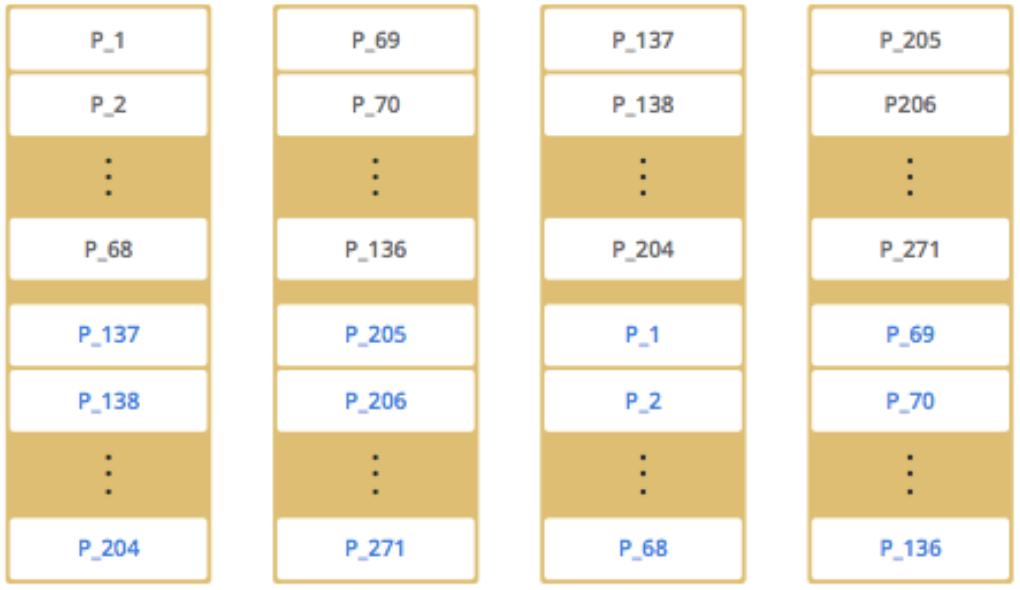
- 노드 추가에 따른 Data Partitioning 전략
- 설명
- Black Text : Primary Partition
- Blue Text : Backup Partition
- Cluster Member(Node)의 추가 및 삭제에 따라
Partition Rebalancing발생.Consistent Hashing Algorithm을 통해, 최소한의 파티션만 Migration.
- 예시
- 1개의 Distributed Cache Cluster

- 2개의 Distributed Cache Cluster - 노드 추가
- 4개의 Distributed Cache Cluster - 노드 추가
- 1개의 Distributed Cache Cluster
- 설명
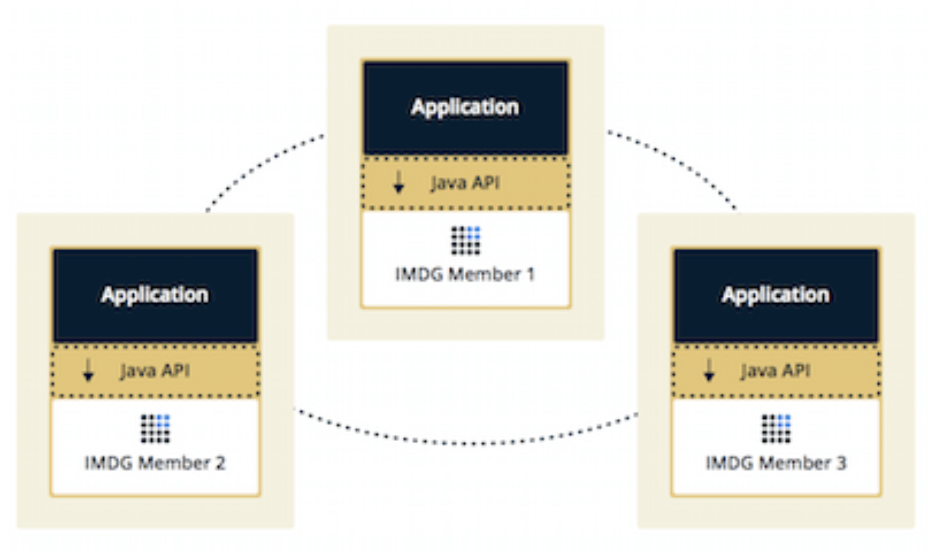
Topology
- Embedded Mode
- Server Client Mode
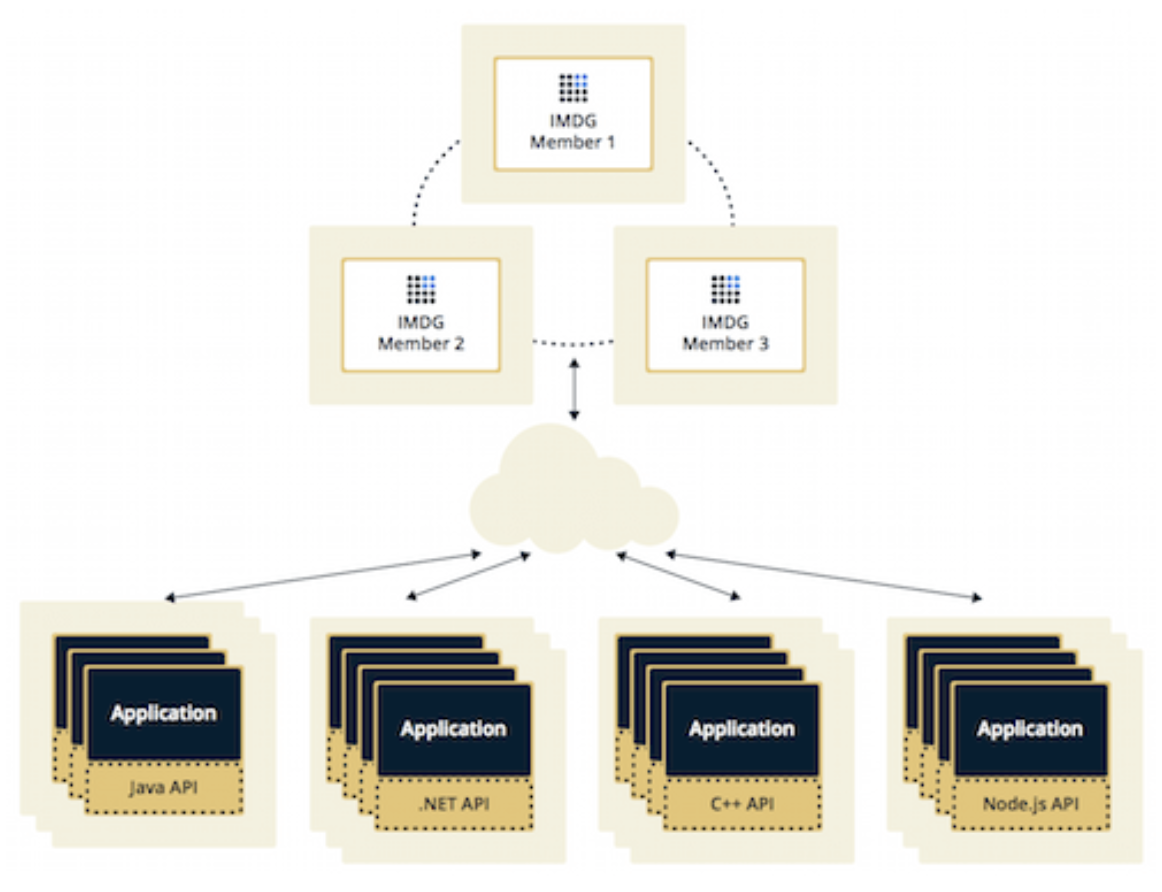
Embedded Mode VS Server Client Mode
- Embedded Mode는 Hazelcast 데이터와 Java API가 동일한 JVM에서 구동됩니다. 따라서, Hazelcast 데이터와 Java API 각각 확장이 불가능합니다.
- Server Client Mode는 Hazelcast 데이터와 Java API가 서로 다른 JVM에서 구동됩니다. 따라서, Hazelcast 데이터와 Java API 각각 확장이 가능합니다.
플랫폼이기에 확장성이 높아야 하므로, 필요에 따라 Hazelcast 데이터 클러스터와 Java API 각각 개별 확장이 가능한 Server Client Mode로 결정하였습니다.
자, 그럼 Topology를 정했으니, 동작 방식을 알아 보도록 하겠습니다.
- Get & Put을 기준으로 아래의 동작 방식에 대해 각각 살펴봅니다.
- Distributed Cache
- Distributed Cache With Near Cache
Hazelcast Distributed Cache 동작 방식
- Get
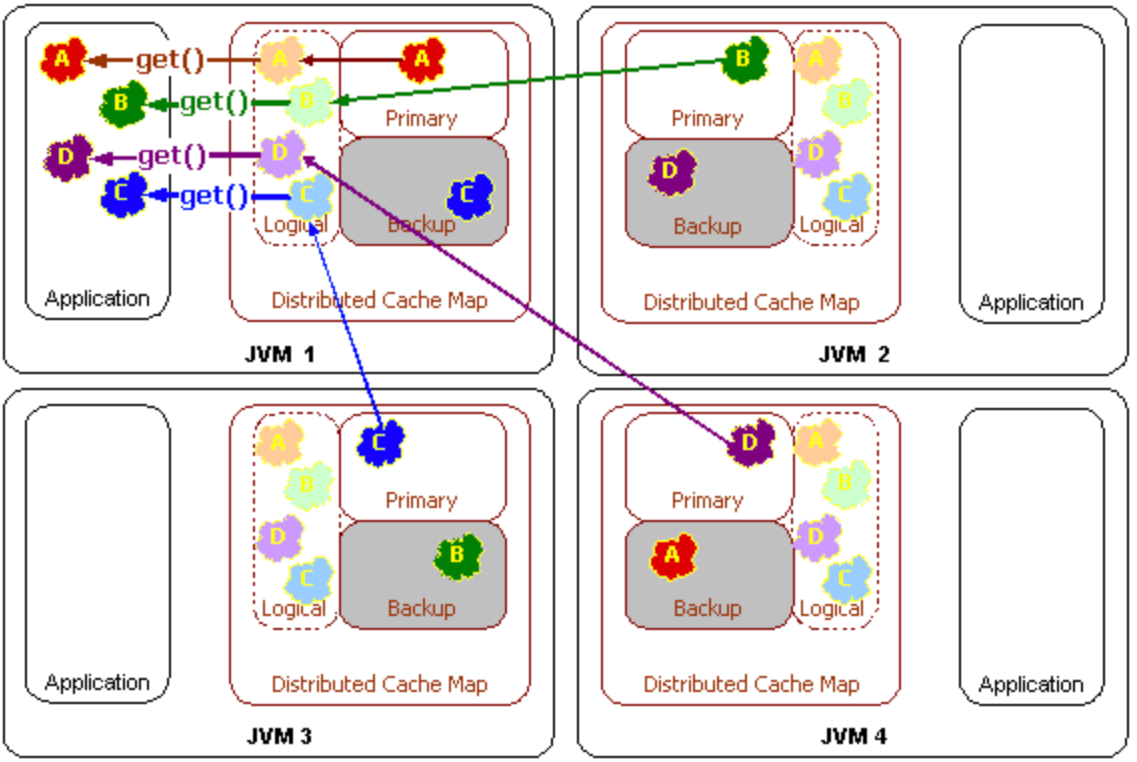
- Put
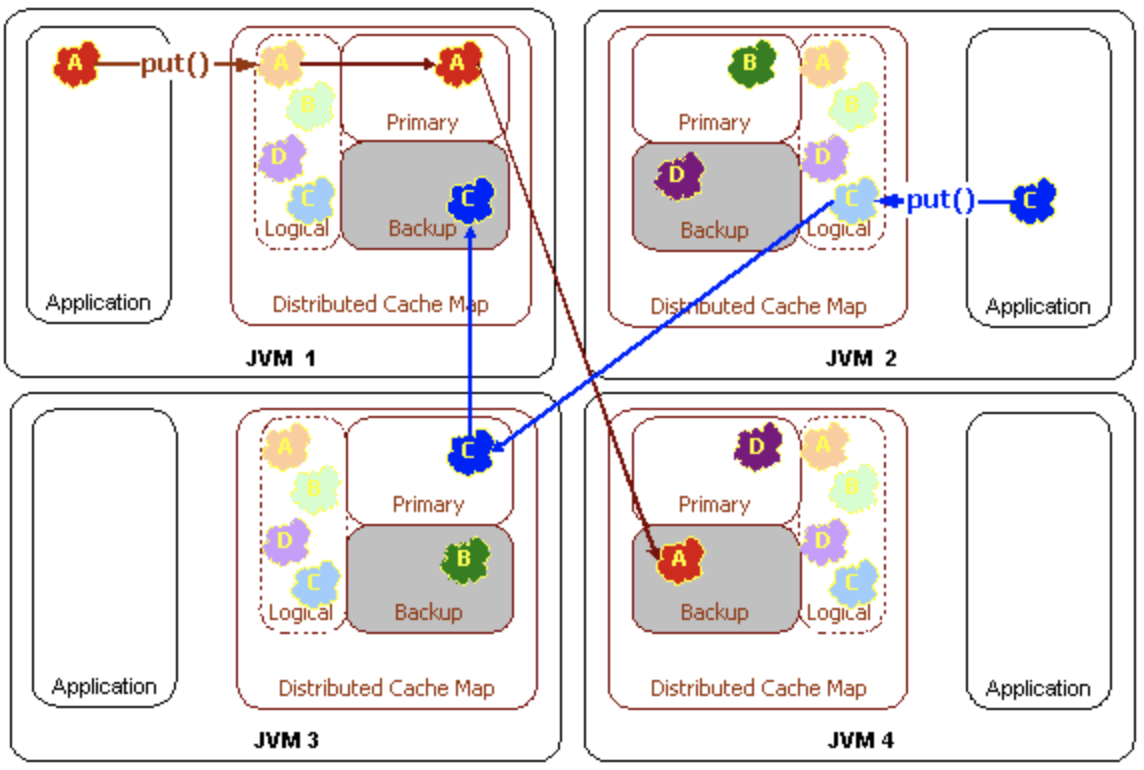
- Get Failover
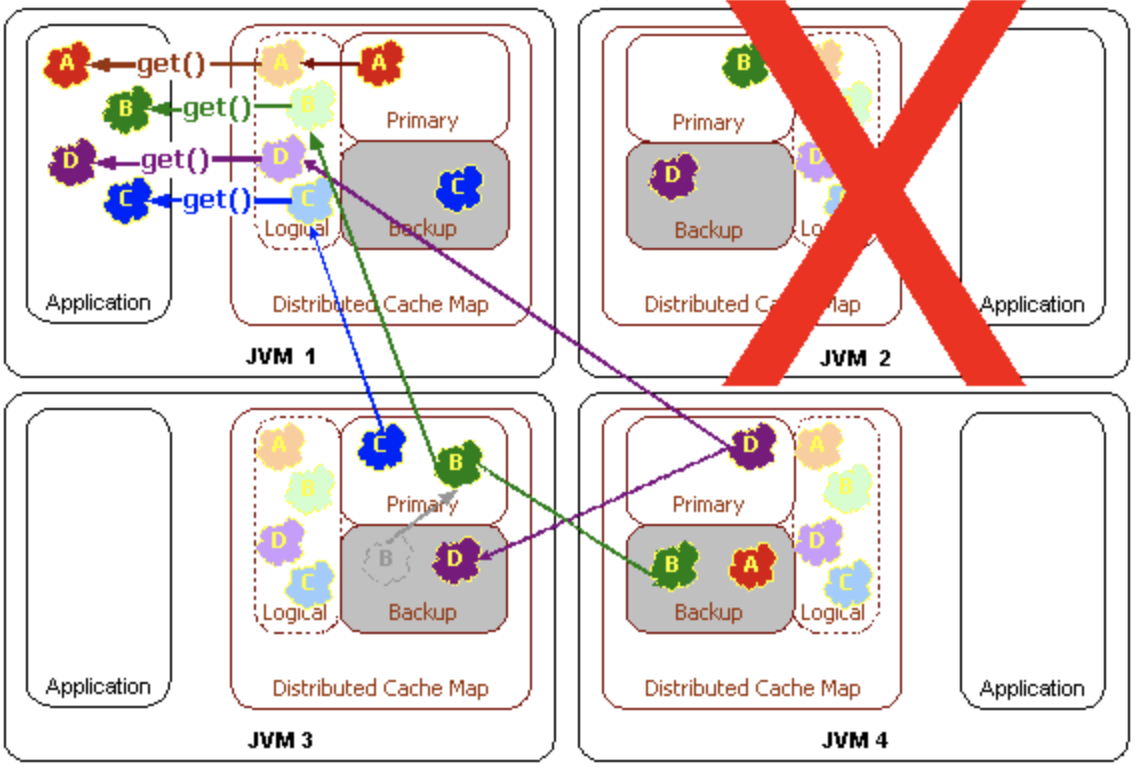
Hazelcast Distributed Cache With Near Cache 동작 방식
- Get
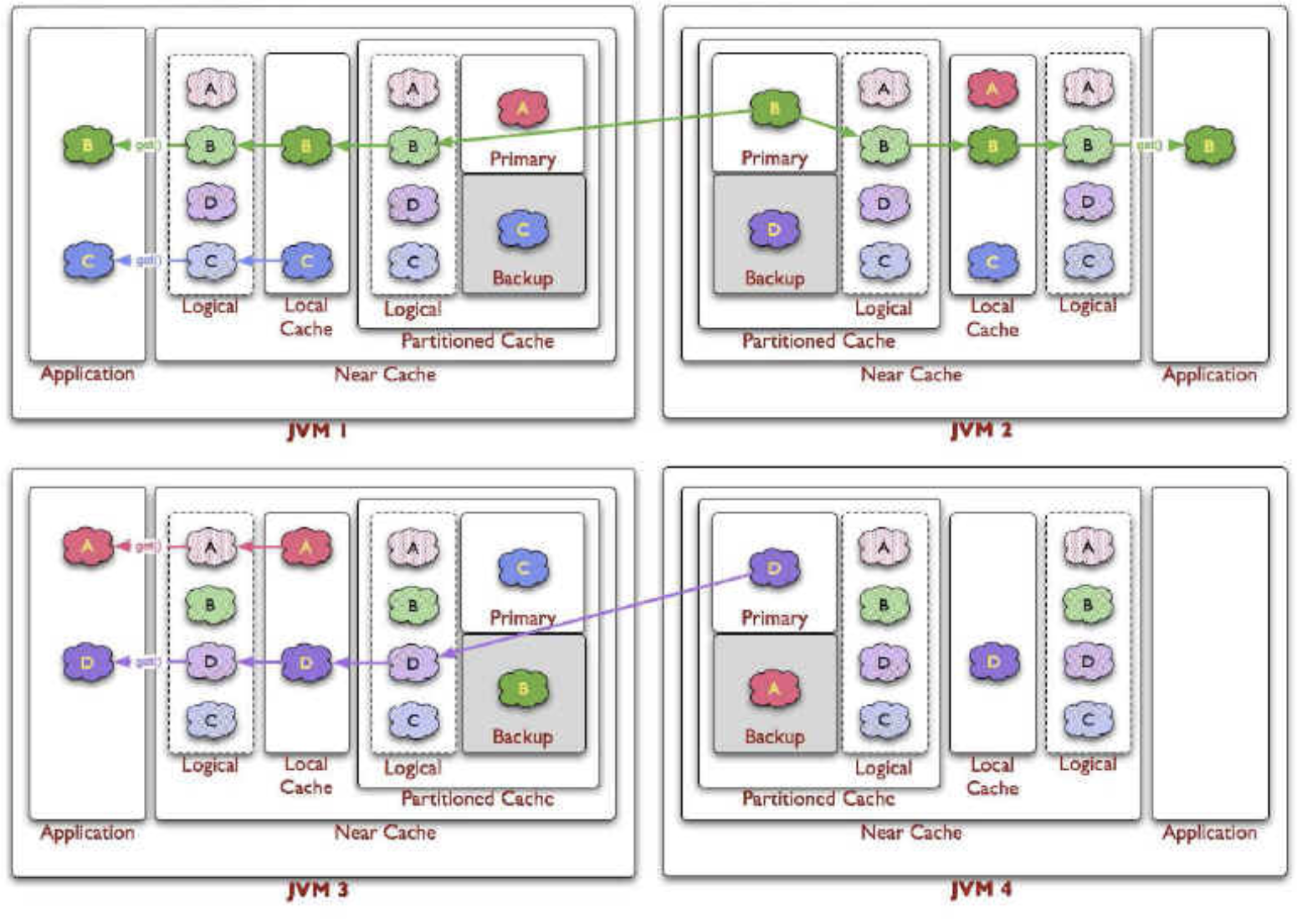
- Put
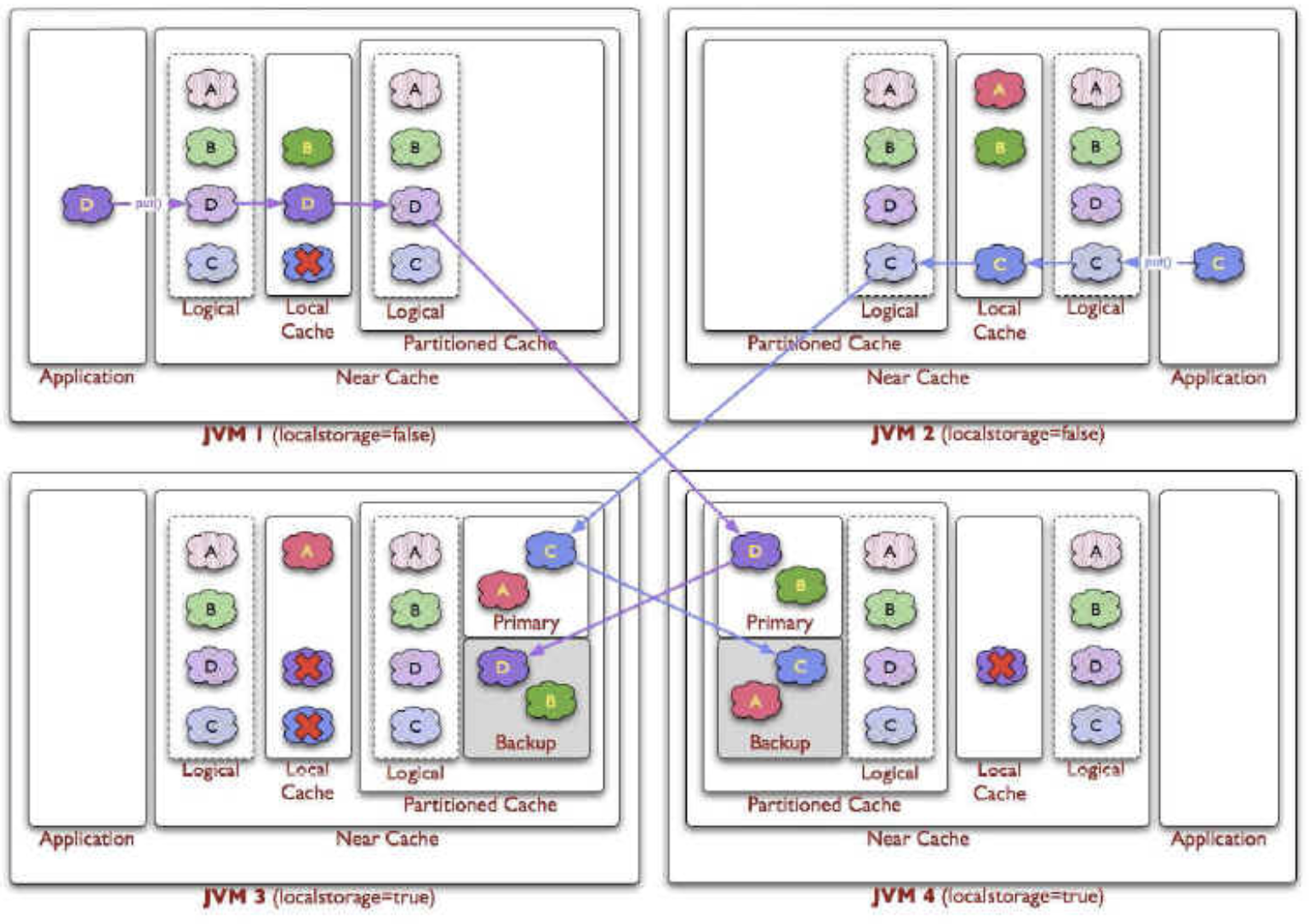
Hazelcast Distributed Cache 그리고 Hazelcast Distributed Cache With Near Cache
- Near Cache는 Clustered Local Cache와 유사하다고 보면 됩니다.
- 따라서, Cache Cluster의 데이터가 변경되면, Cache Cluster에 등록된 Near Cache들 에게 변경 이벤트를 전달하여, 각 Near Cache는 캐시를 깨서 Eventual Consistency를 보장합니다.
- 일반 Local Cache는 각 인스턴스의 변경 사항을 서로가 알 수 없기에 Consistency를 보장하지 않지만, Near Cache는 이를 보장합니다.
- Distributed Cache Cluster에 연결된 Client들은 각각의 Near Cache를 설정하여, Local Heap에 저장된 데이터에 대해서는 Local에서 처리합니다.
- 만약, Client의 Near Cache에 조회하려는 데이터가 없으면, Distributed Cache Cluster를 조회합니다.
- 그리고 Distributed Cache Cluster에도 조회하려는 데이터가 없다면, Database를 조회하게 됩니다.
- 따라서, 자주 사용되는 데이터의 경우 각 Client의 Local Heap에 저장된 Near Cache에서 최대한 처리하여 성능을 향상 시킬 수 있습니다. (I/O 개선)
- 결론,
Get/Put의 비율이 Get이 압도적으로 많으면 로컬에 저장된 Near Cache를 통해, 극적인 성능 향상 효과를 얻을 수 있습니다. - 쿠폰 플랫폼은 Get의 비율이 압도적으로 높기 때문에, Near Cache를 사용합니다.
결론, 그래서 무엇을 해야 하는가 ?
먼저, Server 역할을 하는 Distributed Cache Cluster를 개발.
이후, Client 역할을 하는 API 서버에 Second Level Cache를 적용.
이상, 이론편에서는
적용 배경과 그 목적은 무엇인지 ?
어떻게 Distributed Cache Cluster가 확장성을 제공하는지 ?
시스템 Topology는 어떻게 구성되는지 ?
나아가 Hazelcast Distributed Cache With Near Cache 동작 방식까지 살펴보았습니다.