 pkgonan
pkgonan
목적
- Local Cache 와 Invalidation Message Propagation 전략을 활용하여 API 성능 튜닝하기
배경
- 야놀자 쿠폰 API 서버 개발을 담당하고 있으며, APM Newrelic을 통해 DB Query로 인한 Latency 지연이 전체 Latency의 50%정도를 차지한다는 것을 알게 되었습니다.
- 따라서,
DB Query 조회를 제로에 가깝게 줄여 API 성능을 개선하고자 Cache를 적용하게 되었습니다. 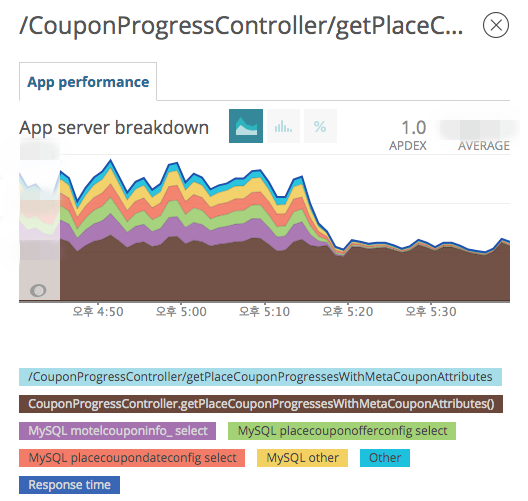
분석
- 현재 쿠폰 도메인의 Entity 사용 패턴을 분석해보았습니다.
- 쿠폰의 메타 데이터 성격의 Entity는 조회가 99.9% 이상으로 압도적으로 많았습니다.
- 이러한 쿠폰 메타 Entity를 전체 트래픽의 95%를 차지하는 상위 3개의 API에서 다수 호출하는 구조였습니다.
따라서, 캐시에 아주 적합한 성격의 Entity라고 판단되었습니다.
Cache를 어떻게 적용할 것인가 ?
- 현재 Hibernate를 ORM으로 사용하고 있습니다.
- 각 API Call 마다 Entity를 중복 조회하고 있었기에, 각 세션 내부에서만 Cache를 공유하는 First Level Cache는 Hit율이 낮은 편이었습니다.
- 만약, 여러 세션에서 Cache를 공유하는 Second Level Cache를 적용할 경우 First Level Cache에서 Miss되는 조회들을 Hit 시킬 수 있게 됩니다.
따라서, 현재 조회 패턴에서 Cache Hit율을 올리기 위해 Hibernate Second Level Cache를 적용하게 되었습니다.
Local Cache vs Remote Cache 어떤 것이 더 적합한 상황인가 ?
쿠폰 메타 Entity에 대해 1초에 수 천번의 극단적인 중복 조회가 이루어지는 상황이었습니다.- 따라서,
성능 측면에서는 매번 Network를 타는 Remote Cache 보다 Local Cache가 가장 적합한 상황이었습니다. - 하지만, Local Cache의 단점은 Entity의 상태가 변경 되었을 때 변경 사항을 다른 인스턴스가 알 수 없다는 것입니다.
- 변경사항을 다른 인스턴스에게 알려주는 솔루션이 없다면 Remote Cache, 있다면 Local Cache 적용을 고려하였습니다.
- 그리고 IMDG로 설계된 Cache 구현체에서 Entity의 상태가 변경되었을때 변경사항을 다른 인스턴스에게 전파하는 기능을 제공하는 것을 확인하게 되었습니다.
- 이에 따라,
극단적인 중복 조회 패턴에서의 퍼포먼스를 위해 Local Cache 적용을 확정하게 되었습니다.
Cache Concurrency Strategy은 어떤 전략이 적합한가 ?
- 현재 Hibernate를 사용하고 있으며, Second Level Cache 적용을 위해 캐시 동시성 전략에 대한 고민이 필요하였습니다.
- Read/Update 비율이 Read가 압도적으로 높고, 동시 수정이 일어날 확률이 낮은 상황이었습니다.
- 따라서,
Lock으로 인한 성능 저하가 없는 NONSTRICT_READ_WRITE 전략이 적합하였습니다.
Cache 구현체의 선택
- Invalidation Message Propagation 기능을 제공하는 Cache 구현체가 필요하였습니다.
- 위와 같은 조건을 기준으로 Cache 구현체 별 적합성에 대해 분석을 해보았습니다. 성능에 대한 차이는 분석에서 제외하였습니다.
-
이름 구분 저장소 적합여부 판단사유 Hazelcast IMDG In Memory O IMDG로 Invalidation Message Propagation 기능 제공 Infinispan IMDG In Memory O 상동 Redis NON-IMDG In Memory X NON-IMDG로 Invalidation Message Propagation 기능 미제공 Ehcache NON-IMDG In Memory X 상동 Ehcache + Terracotta NON-IMDG In Memory X Terracotta 서버 추가 구성으로 인한 부담 - 위 분석을 통해 IMDG에서 분산 메세지 기능을 구현하고 있어, IMDG를 활용해야 한다는 것을 알게 되었습니다.
- 하지만,
Infinispan같은 경우 9.4.9.Final Version 기준으로 Invalidation Mode에서 NONSTRICT_READ_WRITE 전략을 지원하지 않았습니다. - 이에 따라,
NONSTRICT_READ_WRITE 전략을 지원하는 Hazelcast를 Local Cache 구현체로 선택하게 되었습니다.
그래서 Local Cache + Invalidation Message Propagation 전략은 언제 써야 적절한건데 ? (AND 조건)
- 특정 Entity에 대해 조회가 극단적으로 많을 경우
- 극단적인 성능이 필요할 경우
- 조회/수정 비율이 조회가 더 많을 경우 (쿠폰은 약 99.9%/0.1%)
- Eventual Consistency에도 이슈 없는 Entity 속성일 경우
환경
- JAVA 8
- Spring Boot 2.x
- Spring Data JPA 2.x
- Hibernate 5.2.x
- QueryDSL 4.2.x
- Hazelcast 3.11.x
- hazelcast-hibernate52 1.3.x
- AWS Elastic Beanstalk
자주 언급될 단어에 대해 파악해보자
- Hazelcast란 무엇인가요?
- Java 언어로 작성된 Cache 구현체의 한 종류, Multi Thread 기반이며 분산 캐시를 지원하는 오픈 소스
- What is Hazelcast?
- Second Level Cache는 무엇인가요?
- Hibernate에서 First Level Cache는 각 세션 내부에서만 Entity의 상태를 공유하는 캐시 방법 (Default : enable)
- Hibernate에서 Second Level Cache는 여러 세션에서 Entity의 상태를 공유하는 캐시 방법 (Default : disable)
- What is second level cache in hibernate?
Hazelcast 기능
- Hazelcast에서는 어떤 기능들을 제공하는지 살펴보겠습니다.
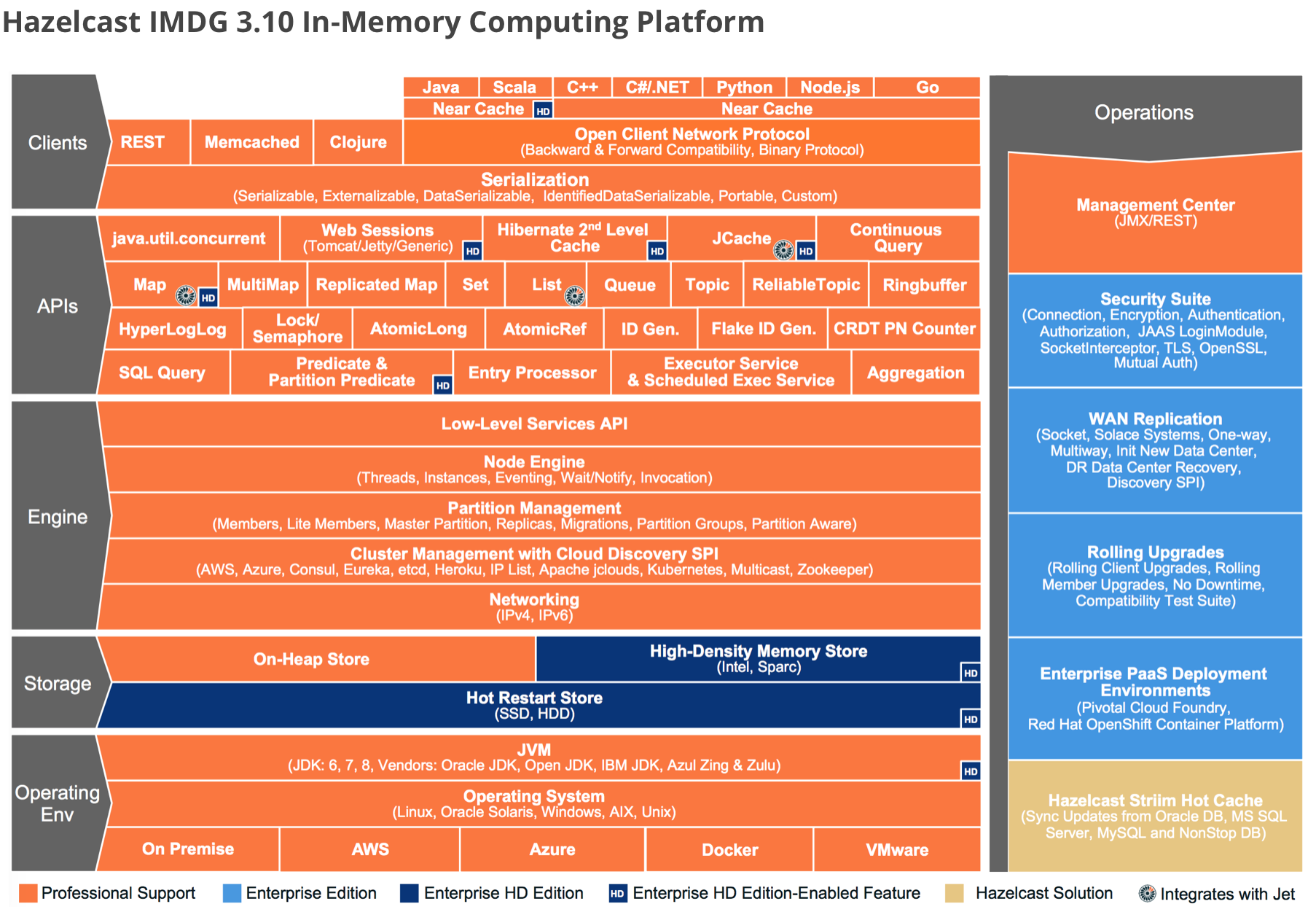
- Operating Env를 통해 Linux, AWS, JVM 환경에서 실행 가능하다는 것을 알 수 있습니다.
- Storage를 통해서는 기본적으로 On-Heap 즉 힙에 저장되는 방식을 사용한다는 것을 알 수 있었습니다. 추가적으로는 유료 사용자에게는 Off-Heap 방식을 제공하고 있습니다.
- API를 살펴본다면, Hibernate Second Level Cache, Set, Map, List, Queue, Topic 등 여러가지 API들을 제공하고 있다는 것을 확인할 수 있습니다.
Hazelcast 배포 방식
- 배포 방식은 두 가지를 제공합니다
- Embedded Mode
- Application 과 Hazelcast Node가 함께 같은 장비(JVM)에서 배포 및 실행
- Client-Server Mode
- Hazelcast Node들만 실행하는 장비가 필요하며, Application 이 배포되는 장비가 추가적으로 필요.
- Embedded Mode
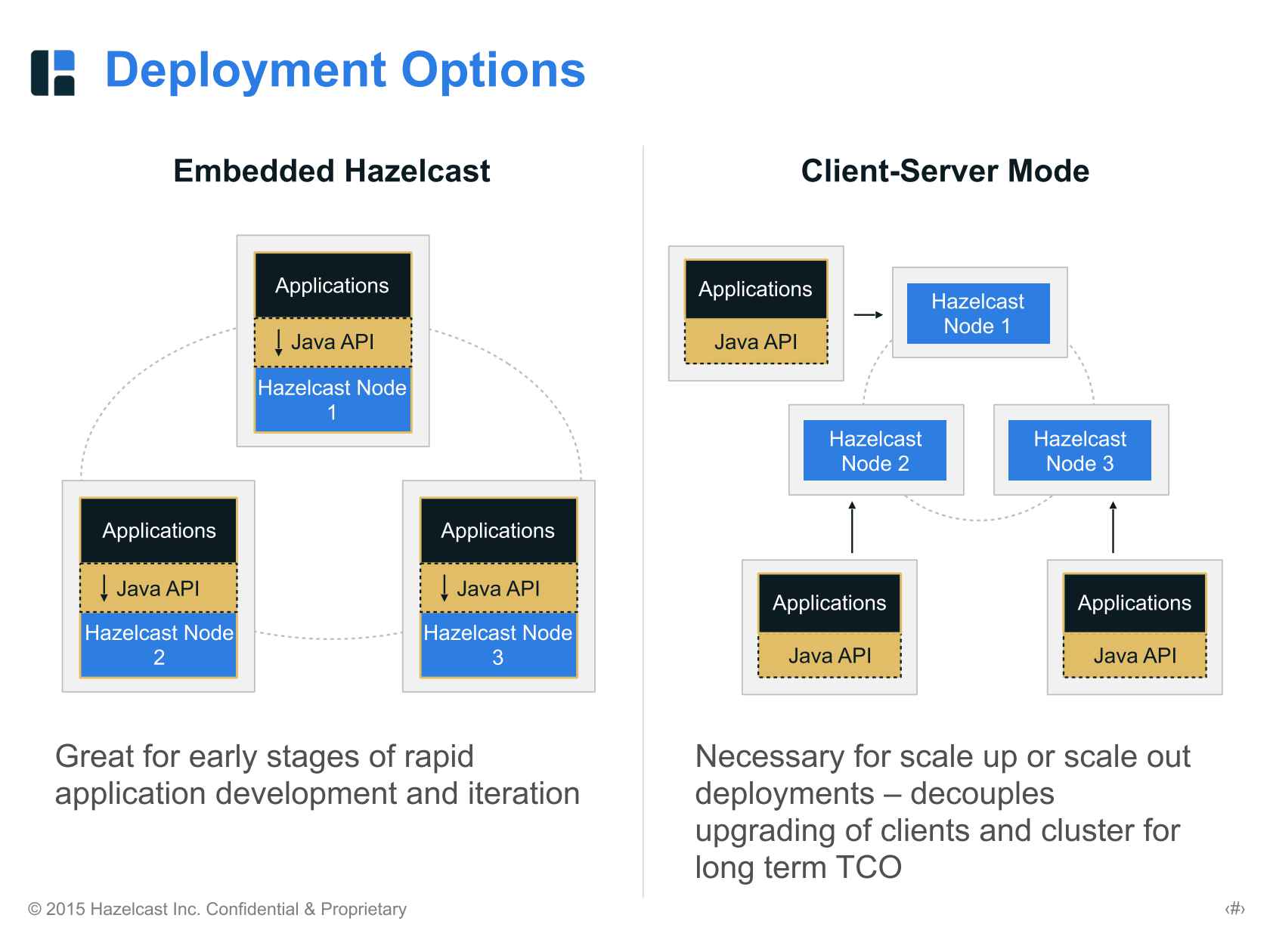
- Deployment Mode의 선택
Embedded Mode는 각 Node 별 동일 JVM에서 실행되기에 개발자의 선택에 따라 데이터를 가져오는데 Network 비용이 들지 않을 수 있습니다Client-Server Mode는 데이터를 가져오려면 항상 Network 비용이 발생합니다.- 후자를 선택할 바에는, AWS Elastic Cache를 사용하는게 더 나을 것 같다는 판단.
- 쿠폰 API에 Second Level Cache를 사용하기 위한 목적이므로 잦은 Entity 조회가 발생하게 될 것이다.
- 따라서, 하나의 Entity를 가져오는데 2ms가 걸릴 경우, 5개의 Entity를 가져오는 비지니스 로직의 경우 10ms가 걸리게 될 것입니다.
Network Latency를 0에 수렴할 목적으로 Embedded Mode를 선택.
Hazelcast 클러스터링
- 클러스터링이란 무엇일까요?
- 같은 것 끼리 묶는 것.
- 여러 인스턴스들 중 같은 유형끼리 논리적으로 묶어 취급하는 것.
- Hazelcast에서 제공하는 클러스터링 방법
- Multicast discovery
- Discovery by TCP/IP
- AWS EC2 discovery by TCP/IP
- jclouds® for discovery
- 클러스터링 방법의 선택
- 현재 쿠폰 API는 AWS Beanstalk 환경에서 운영중이기에, AWS Discovery 방식을 선택하게 되었습니다.
- hazelcast-aws의
Discovery SPI 기능을 활용하여 AWS Beanstalk 환경에서 여러대의 인스턴스를 클러스터링합니다. -
AWS에서 제공하는 API를 호출 하여 인스턴스의 메타 정보를 가져와 TCP 통신을 통해 클러스터링합니다.
com.hazelcast.aws.utility.MetadataUtil.java /** * Performs the HTTP request to retrieve AWS Instance Metadata from the given URI. * * @param uri the full URI where a `GET` request will retrieve the metadata information, represented as JSON. * @param timeoutInSeconds timeout for the AWS service call * @param retries number of retries in case the AWS request fails * @return The content of the HTTP response, as a String. NOTE: This is NEVER null. */ public static String retrieveMetadataFromURI(final String uri, final int timeoutInSeconds, int retries) { return RetryUtils.retry(new Callable<String>() { @Override public String call() { return retrieveMetadataFromURI(uri, timeoutInSeconds); } }, retries); }
- AWS Beanstlak 환경에서 Hazelcast Clustering 적용하기
- 반드시,
VPC Security Group의 인바운드 규칙의 TCP Port를 반드시 열어야합니다. - Default Port인 5701 부터 사용하려는 Port를 열어두어야 합니다.
- 클러스터링이 정상적으로 되지 않으면 Cache Eviction 등의 기능들이 정상적으로 동작하지 않아, 꼭 확인해야 합니다.
- 반드시,
Hazelcast 데이터 적재 방식
- Hazelcast 데이터 적재 방식은 ?
- 분산 처리 방식 (HazelcastCacheRegionFactory)
데이터 Put & Get 시 Clustering 된 Instance에 분산하여 처리한다.- 장점으로는 여러대의 Instance에 중복된 데이터가 저장되지 않는다.
- 단점으로는 데이터를 적재하고 가져올때 Network Time이 발생한다.
- 당연하게도 Read / Update 비율이 Read 가 많아야지 Update가 많으면 비효율.
Cache 데이터가 변경 되었을 때 Multicasting을 통해 타 인스턴스에 Invalidation 요청을 전달한다.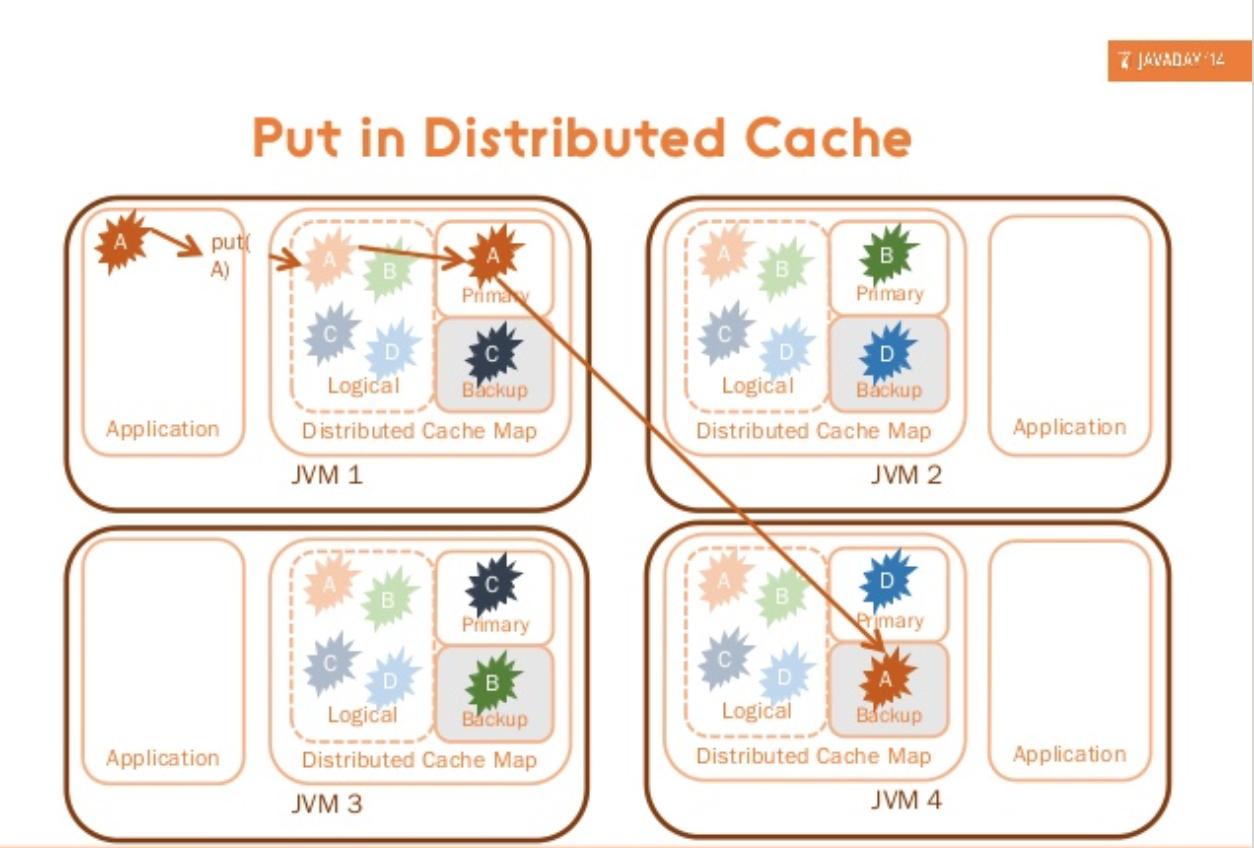
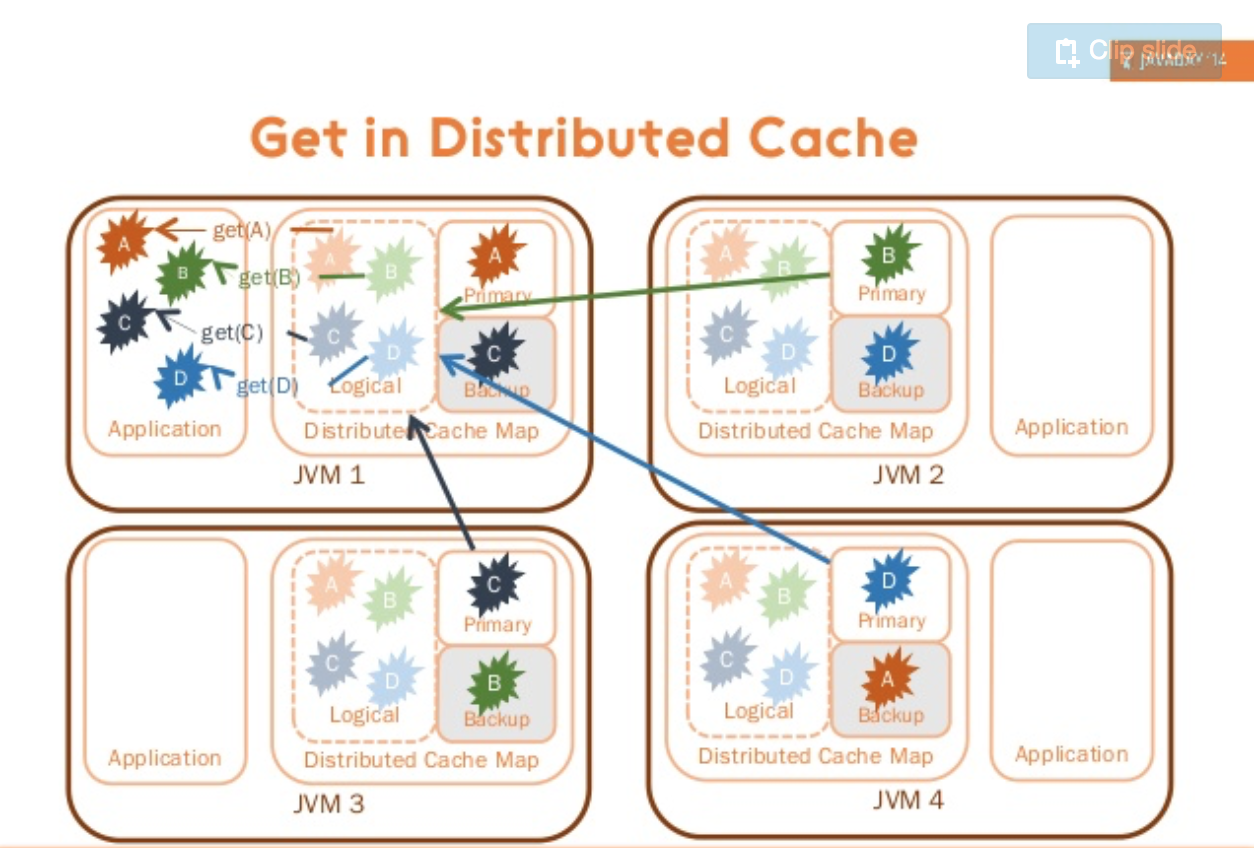
- Local 처리 방식 (HazelcastLocalCacheRegionFactory)
데이터 Put & Get 시 Clustering 된 Instance에 각각 따로 적재 및 처리한다.- 장점으로는 Local에서 데이터를 가져오고 적재하기 때문에 Network Time이 발생하지 않아 빠르다.
- 단점으로는 여러대의 Instance에 중복되는 데이터가 발생한다.
- 당연하게도 Read / Update 비율이 Read 가 많아야지 Update가 많으면 비효율.
Cache 데이터가 변경 되었을 때 Multicasting을 통해 타 인스턴스에 Invalidation 요청을 전달한다.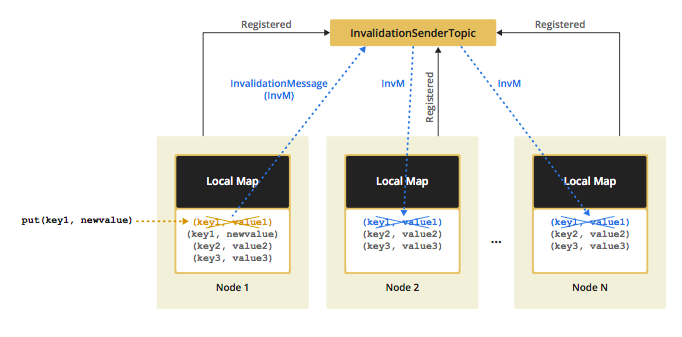
- 분산 처리 방식 (HazelcastCacheRegionFactory)
- Coupon API의 Hazelcast Second Level Cache 데이터 적재 방식의 결정
- 데이터 적재 방식의 결정을 위해서 고려한 부분은 크게 두 가지 였습니다.
- 성능 그리고 AWS Beanstalk 환경에서의 배포 이슈 여부
- 성능 측면
- Second Level Cache를 통해 Entity 즉 Table 단위의 캐시를 하므로, 빈번한 캐시 조회가 예상되는 상황이었습니다.
- 따라서,
극한의 성능을 위해서는 Network Time이 발생하지 않는 Local에서 처리하는 방식이 적합하였습니다.
- 배포 측면
- Cache가 AWS Beanstalk에서 제공하는 Rolling Update & Blue Green Deploy로 인해 이슈가 발생하면 안됩니다.
- 만약 분산하여 처리하는 방식을 선택하게 될 경우, 데이터가 분산되어 저장되게 되면서 해당 이슈가 발생하게 됩니다.
- 예를 들면, Entity에 Colum을 새로 추가하거나 제거하고 새로 배포할 경우 발생 가능합니다.
- 데이터를 분산하여 적재 후, Rolling Update로 Entity에 새로운 Colum을 추가한 후 해당 데이터를 요청해보면 아직 Update가 되지 않는 Instance에서 데이터를 가져오게 되어 정합성이 깨지게 됩니다.
- 따라서,
배포시 발생할 수 있는 Serialization & Deserialization 이슈를 회피하기 위해서는 Local에서 처리하는 방식이 적합하였습니다.
- 성능 측면
성능과 배포에 대해 종합적으로 판단한 결과 Local에서 데이터를 적재하고 처리하는 방식이 쿠폰 API에서 더 적합하다는 결론을 내었습니다.
Hazelcast 분산 이벤트
- Hazelcast 분산 이벤트 사용처는 ?
Cache 대상이 되는 데이터가 Update 될 경우, 상태가 변경이 되었다는 Event를 클러스터링 된 다른 인스턴스에 Propagation(Multicast) 하는데 사용됩니다.- 이벤트 리스너에서는, 이벤트 수신시 해당 캐시를 Eviction 할 것인지, 아니면 Update할 것인지 설정을 통해 선택 가능.
- 컬럼이 추가 혹은 삭제될 경우 등등 여러가지 Serialization 이슈가 존재.
- 따라서, 이벤트를 수신하면 해당 이벤트에 해당하는 Cache를 Eviction 할 것을 개인적으로 추천.
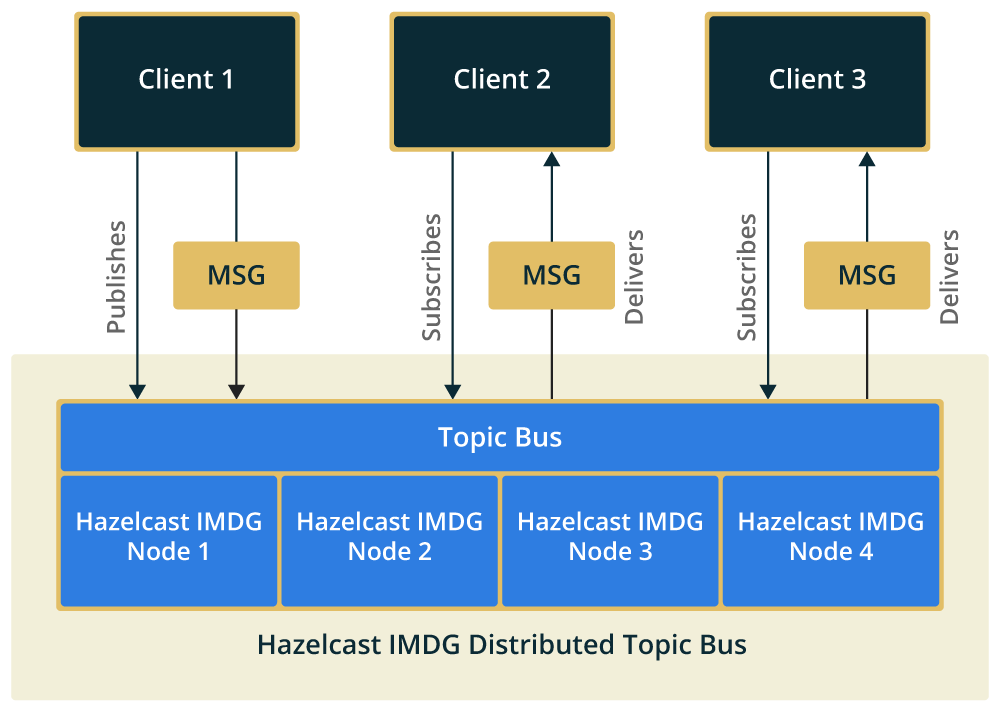
- Distributed Event 전송 방식
Pub / Sub 패턴- Clustering 된 Hazelcast Node들은 서로를 인식 하고 있습니다.
- 각 Node들은 Publish하는 이벤트들의 Subscriber를 알고 있으며, 해당 Node의 IP 주소를 알고 있습니다. (처음 서버 실행시 클러스터링을 통해 인식)
-
따라서,
특정 이벤트가 Publish 되면, 해당 이벤트를 Subscribe하고 있는 Node들을 가져와서 Loop를 돌며 데이터를 전송com.hazelcast.spi.impl.eventservice.impl.EventServiceImpl.java @Override public void publishEvent(String serviceName, Collection<EventRegistration> registrations, Object event, int orderKey) { Data eventData = null; for (EventRegistration registration : registrations) { if (!(registration instanceof Registration)) { throw new IllegalArgumentException(); } if (isLocal(registration)) { executeLocal(serviceName, event, registration, orderKey); continue; } if (eventData == null) { eventData = serializationService.toData(event); } EventEnvelope eventEnvelope = new EventEnvelope(registration.getId(), serviceName, eventData); sendEvent(registration.getSubscriber(), eventEnvelope, orderKey); } }
- Distributed Event 동기 & 비동기 전송
기본적으로 비동기 전송을 한다.- 기본적으로 Default 값인
100,000 번째 요청마다 동기 전송을 수행한다. (10만, 20만, 30만… 째 마다)- EVENT_SYNC_FREQUENCY = 100000
- 데이터 전송 실패를 처리하는 방식
전송 실패 처리 방식에서의 데이터 신뢰도와 성능은 반비례
Hazelcast에서 Local Cache + Invalidation Message Multicasting 방식에서는 Retry 정책을 사용- 동기식 전송일 경우 재시도 회수 50
-
비동기식 전송일 경우 재시도 회수 5
com.hazelcast.spi.impl.eventservice.impl.EventServiceImpl.java private void sendEvent(Address subscriber, EventEnvelope eventEnvelope, int orderKey) { String serviceName = eventEnvelope.getServiceName(); EventServiceSegment segment = getSegment(serviceName, true); boolean sync = segment.incrementPublish() % eventSyncFrequency == 0; if (sync) { SendEventOperation op = new SendEventOperation(eventEnvelope, orderKey); Future f = nodeEngine.getOperationService() .createInvocationBuilder(serviceName, op, subscriber) .setTryCount(SEND_RETRY_COUNT).invoke(); try { f.get(sendEventSyncTimeoutMillis, MILLISECONDS); } catch (Exception e) { syncDeliveryFailureCount.inc(); if (logger.isFinestEnabled()) { logger.finest("Sync event delivery failed. Event: " + eventEnvelope, e); } } } else { Packet packet = new Packet(serializationService.toBytes(eventEnvelope), orderKey) .setPacketType(Packet.Type.EVENT); if (!nodeEngine.getNode().getConnectionManager().transmit(packet, subscriber)) { if (nodeEngine.isRunning()) { logFailure("Failed to send event packet to: %s, connection might not be alive.", subscriber); } } } }
- 분산 메세징을 통한 Cache Invalidation Message Propagation 방식의 신뢰성 분석
- 인스턴스간의 Cache Invalidation Message Propagation 도달 시간 차이로 인한 신뢰성 문제에 대하여
당연하게도 미세한 시간 차이가 존재, 그 시간 사이에서는 Consistency를 보장 불가- 데이터 원본이 한곳에 저장되는 방식이라면 Consistency 보장 가능
- 쿠폰에서는 데이터를 각자 Local에 저장하는 방식을 사용, 미세한 Consistency 이슈 존재
즉, 변경이 적은 데이터를 캐시해야 하며, 변경으로 인해 크리티컬한 이슈가 발생하지 않는 데이터를 적재해야 할 것- 쿠폰 API에서는 데이터가 변경되어도 그 영향이 적은 Entity들을 캐싱
- 따라서, 쿠폰 API에서는 Propagation 시간 차이로 인한 Consistency 이슈 없음
- 네트워크 혹은 서버상의 이슈로 Cache Invalidation Message를 받지 못해 생길 수 있는 Consistency 문제에 대하여
- 네트워크 상의 통신 문제로 인한 문제
TCP 전송방식을 사용, 패킷 유실 등은 프로토콜에서 재처리, 이슈 없음
- 동작중인 서버가 OOM 등에 의해 정지한 경우
- (OOM등에 대한 적절한 처리, 판단 후),
결론적으로 인스턴스가 재실행되기만 하면 된다 (캐시가 비워질 것이므로), 이슈 없음
- (OOM등에 대한 적절한 처리, 판단 후),
- 동작중인 서버에서 일시적으로 500에러 발생으로, 로드밸런서에서 해당 인스턴스를 제외했다가 다시 포함한 경우
로드밸런서를 통하지 않고, 인스턴스간에 직접 통신을 하므로 Cache Eviction은 정상적으로 이루어진다. 이슈 없음
- 동기 & 비동기 이벤트가 각각 최대 재시도 회수인 50회, 5회를 넘길 경우 ?
- 개인적으로 장애 상황으로 판단하였다.
- 데이터 전송 실패를 처리하는 여러가지 방법 중, Retry를 사용하는데 몇번까지 재시도를 할 것인가는 정책상의 문제로 보인다.
- Server <-> Server 직접 TCP 통신, 인스턴스 CPU 사용률이 과도하여 못받는다던지, Thread를 할당받지 못한다던지.
- 네트워크 상의 통신 문제로 인한 문제
- 인스턴스간의 Cache Invalidation Message Propagation 도달 시간 차이로 인한 신뢰성 문제에 대하여
Hazelcast 적용
- 캐시를 담을 Map 설정
- Cache Map Size
- 각 Entity 별 차등을 두어 적용하였습니다.
- 운영중인 서비스의 특성상 여름 성수기의 쿠폰 사용이 많은 편이라 여름 성수기 기준으로 설정을 하였습니다.
- Cache Eviction Strategy
LRU
- Cache Eviction Interval
-
60초마다 Eviction을 담당하는 Thread가 Eviction 처리
com.hazelcast.hibernate.local.CleanupService.java public final class CleanupService { private static final long FIXED_DELAY = 60; private static final long FIXED_DELAY1 = 60; private final String name; private final ScheduledExecutorService executor; public CleanupService(final String name) { this.name = name; executor = Executors.newSingleThreadScheduledExecutor(new CleanupThreadFactory()); } public void registerCache(final LocalRegionCache cache) { executor.scheduleWithFixedDelay(new Runnable() { @Override public void run() { cache.cleanup(); } }, FIXED_DELAY, FIXED_DELAY1, TimeUnit.SECONDS); } } com.hazelcast.hibernate.local.LocalRegionCache.java void cleanup() { final int maxSize; final long timeToLive; if (config != null) { maxSize = config.getMaxSizeConfig().getSize(); timeToLive = config.getTimeToLiveSeconds() * SEC_TO_MS; } else { maxSize = MAX_SIZE; timeToLive = CacheEnvironment.getDefaultCacheTimeoutInMillis(); } boolean limitSize = maxSize > 0 && maxSize != Integer.MAX_VALUE; if (limitSize || timeToLive > 0) { List<EvictionEntry> entries = searchEvictableEntries(timeToLive, limitSize); final int diff = cache.size() - maxSize; final int evictionRate = calculateEvictionRate(diff, maxSize); if (evictionRate > 0 && entries != null) { evictEntries(entries, evictionRate); } } }
-
- Cache Map Size
- Cache Hit율 극대화 전략
- 배경
기본적으로 Second Level Cache는 findById() Primary Key로 단건 조회일때만 HitfindAllById() 등은 Hit가 되지 않음(Composite Key는 예외)- 쿠폰 API에서는 많은 쿼리들이 findAllById로 동작.
- 따라서,
findAllById() 일때 Hit율을 높여 성능을 최적화하는게 핵심. 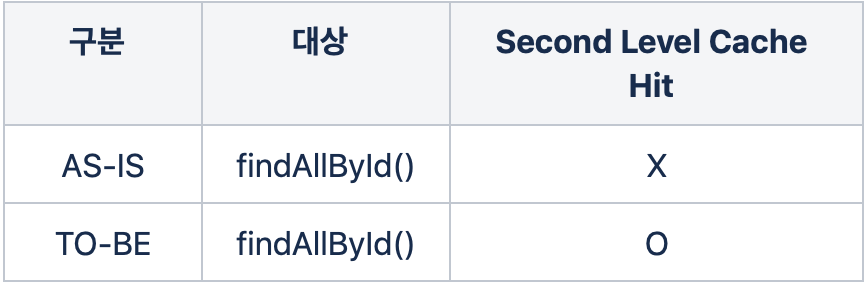
-
전략
List<Entity> 엔티티 결과들; List<Key> 존재하지 않는 Keys; For (Long id : ids) { 데이터가 Second Level Cache에 존재하는지 확인 if (존재하면, findById() 로 조회하여 Cache Hit, 반환할 엔티티 결과들 List<Entity>에 담는다.) else (존재하지 않으면, 존재하지 않는 Key를 모으는 List<Key>에 Primary Key를 담는다.) } 존재하지 않는 Key를 모으는 List<>가 비어있지 않으면, 해당 Key들로 findAllById() 하여 DB 조회하여 가져와 엔티티 결과들에 담는다. 엔티티 결과들을 반환한다. ; -
전략의 구현
interface TestCouponCustomRepository { List<TestCoupon> findAllByCachedId(Iterable<Long> ids); } class TestCouponRepositoryImpl implements TestCouponCustomRepository { @Autowired private EntityManager entityManager; @Autowired private TestCouponRepository testCouponRepository; /** * findAllById Second Level Cache Hit 적용 * Second Level Cache에 존재하는 ID는 가져오고, 없는 ID들만 모아서 DB 조회 **/ @Override public List<TestCoupon> findAllByCachedId(Iterable<Long> ids) { List<TestCoupon> testCoupons = Lists.newArrayList(); List<Long> notExistIds = Lists.newArrayList(); Cache secondLevelCache = entityManager.getEntityManagerFactory().getCache().unwrap(Cache.class); for (Long id : ids) { boolean existSecondLevelCache = secondLevelCache.contains(TestCoupon.class, id); if (existSecondLevelCache) { testCouponRepository.findById(id).ifPresent(testCoupons::add); } else { notExistIds.add(id); } } if (!notExistIds.isEmpty()) { testCoupons.addAll(testCouponRepository.findAllById(notExistIds)); } return testCoupons; } }
- 배경
Hazelcast 적용 결과
- 목표
- Coupon API의 응답 속도 향상
- DB 트래픽 경감
- 결과
Coupon API 100% 이상 성능 향상- 리스트용 쿠폰 실시간 집계 API (
쿠폰 전체 트래픽의 약 20% 비중)150% 성능 향상
- 쿠폰 실시간 집계 API (
쿠폰 전체 트래픽의 약 27% 비중)100% 성능 향상
- 예약시 사용가능한 쿠폰 조회 API (
쿠폰 전체 트래픽의 7% 비중)71% 성능 향상
- 리스트용 쿠폰 실시간 집계 API (
- DB 트래픽 약 30% 경감
- 결과 이미지
- Cache 적용 이후 전체 Latency 변화
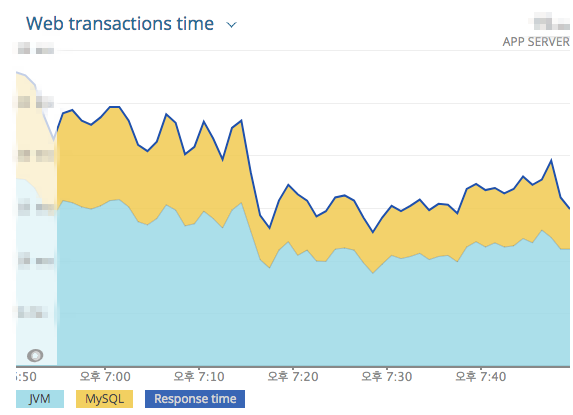
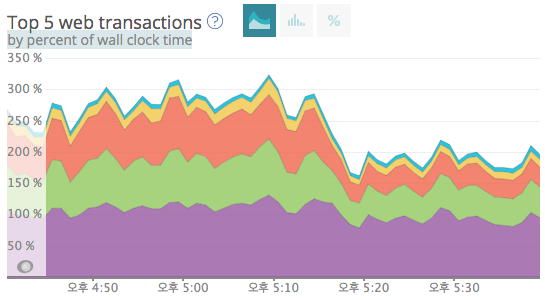
- Cache 적용 이후 TOP 5 트래픽 API Transaction 시간 변화
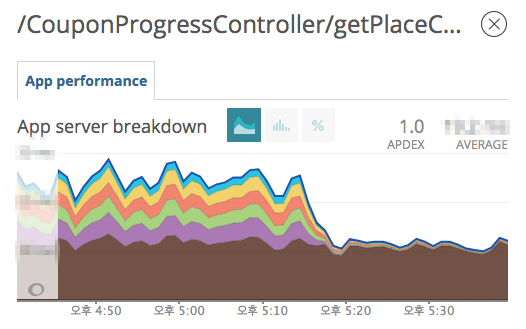
- Cache 적용 이후 리스트용 쿠폰 실시간 집계 API 변화
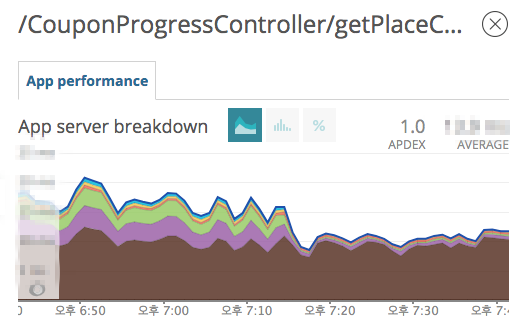
- Cache 적용 이후 쿠폰 실시간 집계 API 변화
- Cache 적용 이후 예약시 사용가능한 쿠폰 조회 API 변화
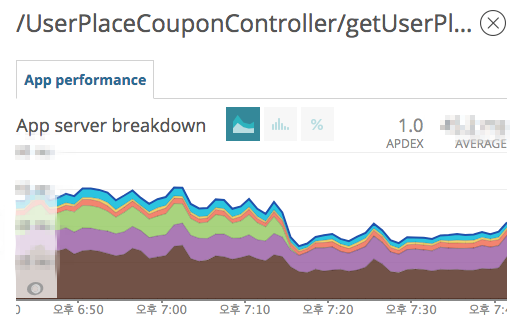
- Cache 적용 이후 DB 트래픽 변화
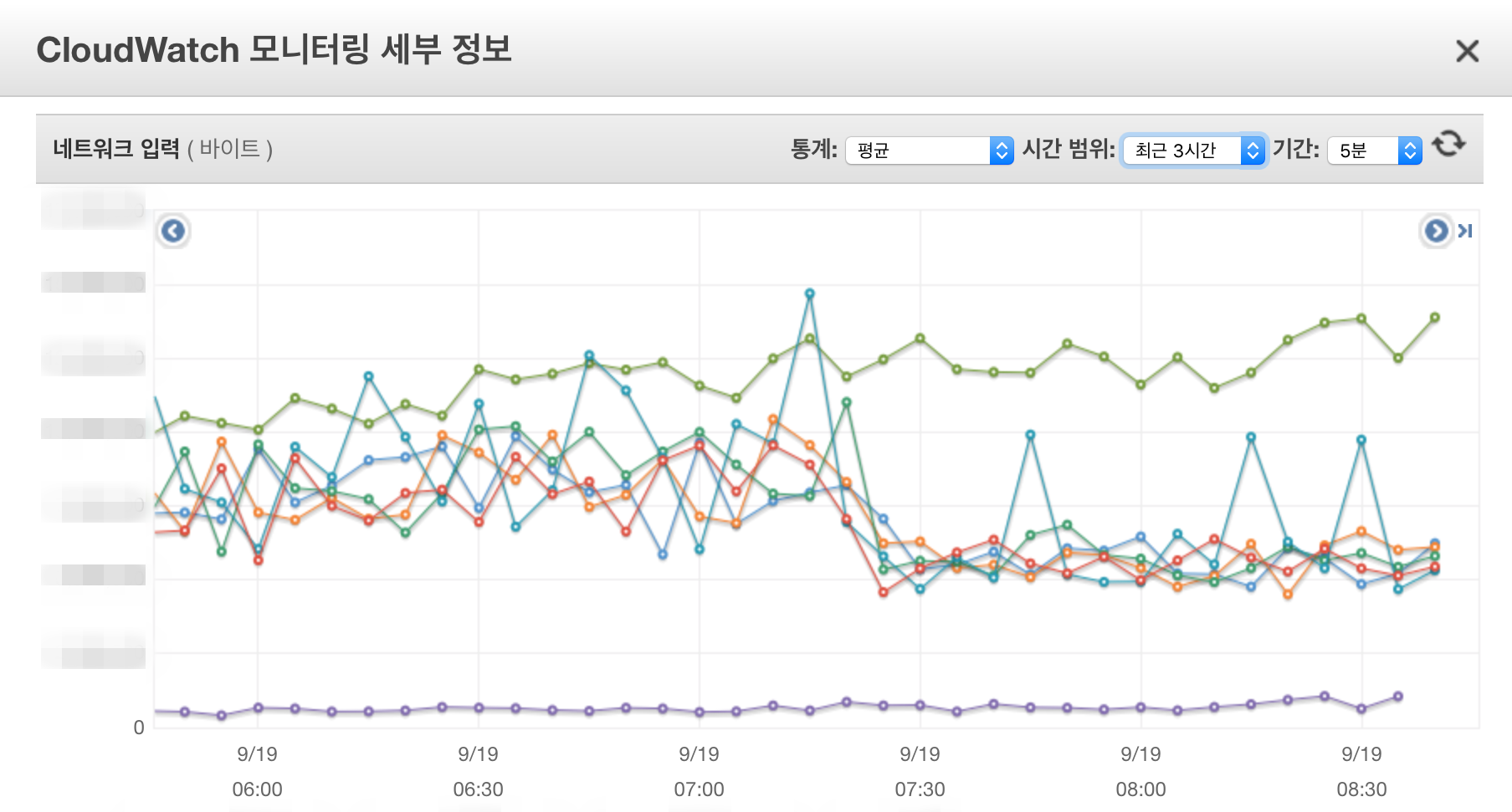
마치며
- 캐시 적용 전후, APM에서 Latency 그래프가 극단적으로 깎여 나가는 것을 보면 쾌감이 상당합니다…
- 성능 튜닝의 시작은 APM인 것 같습니다.
- 어플리케이션의 어떤 부분이 성능에 영향을 미치는지 현 상황을 분석하기 위해서는 APM이 필요하며, 이를 통해 개선포인트를 찾을 수 있는 Insight를 얻을 수 있기 때문입니다.
- 모든 것은 Trade Off, 분산 환경에서 Local Cache는 성능과 Strong Consistency를 함께 지킬 수 없습니다.
- 사용하려는 서비스의 특징 그리고 읽기/쓰기의 비율이 읽기가 많은지, 데이터 수정으로 인해 크리티컬한 이슈가 발생하지 않는 데이터인지를 잘 고려하여 사용하면 극적인 퍼포먼스를 내는 좋은 솔루션이 될 수 있을 것 같습니다.
- Local Cache로 인한 성능 극대화와 Heap의 압박을 함께 고려하여 장점이 단점보다 클 경우에 사용할 것을 추천합니다.