 pkgonan
pkgonan
주제
- Distributed Cache로 Hibernate Second Level Cache를 적용하여 성능 튜닝하기 - Distributed Cache Cluster 개발편
목적
- 확장성 및 성능을 함께 고려한 분산 캐시 클러스터로 Client를 지원한다.
분석
- 확장성은 어떻게 제공하는가 ?
Cache Cluster는 Distributed Cache로 Scale Out을 통해 데이터의 확장성을 얻는다.
- 성능은 어떻게 제공하는가 ?
Cache Cluster를 이용하는 Client는 Near Cache를 통해 자주 사용되는 데이터는 Local에서 최대한 처리하여 성능을 얻는다.
- Consistency는 어떤 것을 제공하는가 ?
Strong Consistency를 보장하지 않으며, Eventual Consistency를 제공한다. 따라서, 이에 적합한 데이터를 Client가 선별하여 저장해야 한다.
Hazelcast 특성
- In Memory에서 처리되어 빠른 성능을 제공합니다.
- 분산 시스템 CAP 이론 중, AP를 지원합니다.
- CP Subsystem이라는 특정 자료구조 그룹은, 분산시스템 합의 알고리즘 중 Raft Algorithm 기반으로, CAP 이론 중, CP를 지원합니다.
- 따라서,
저장하려는 데이터가 Eventual Consistency에 적합한지 개발자가 선별해서 저장해야 합니다.
Minimum Instance
- 분산 시스템의 특성상,
고가용성을 위해 최소 3개의 인스턴스가 필요합니다.- 3, 5, 7 등 홀수의 인스턴스로 운영이 필요합니다.
Split Brain Protection
분산 시스템에서 발생 가능한 Network 단절 현상 (Split Brain) 보호 기능을 적용하였습니다.- X : Minimum cluster size for split brain protection
- Y : Cluster size (AWS ElasticBeanstalk Instance)
- X = Y / 2 + 1
-
예시
- 3개의 인스턴스로 클러스터 운용시
- X = 3 / 2 + 1
- X = 2
- 즉, 최소 2대 이상의 멤버를 보유한 클러스터에 대해 처리를 가능하게 합니다.
-
상세 설명
- Split Brain 현상 발생시, 과반수의 클러스터를 살리고 과반수에 도달하지 않는 클러스터의 처리를 막아 데이터 Consistency 오류를 방지합니다.
- 3개의 인스턴스로 1개의 클러스터 운용 중 - Split Brain 현상 발생
- 2개의 인스턴스 클러스터 1개 및 1개의 인스턴스 클러스터 1개로 쪼개집니다.
- 이때 과반수인 2대의 인스턴스 클러스터의 처리를 가능하게하고, 1대의 인스턴스 클러스터는 처리를 막습니다.
- 이후, Split Brain 현상을 탐지하고 Merge 시키는 Thread를 통해 머지합니다.
- Merge Policy는 MergePolicyConfig를 참조합니다.
- 현재, Split Brain Protection은 WRITE에 대해서만 방지합니다.
- READ는 허용하여 장애를 최소화 합니다.
- WRITE가 데이터를 변경시켜 Consistency 불일치 현상을 발생시킬 수 있으므로, WRITE에 대해서만 방지합니다.
Hazelcast Distributed Cache Cluster 개발하기
-
첫째, application-{environment}.yml
hazelcast: cluster: aws: environment-name: ${EB_ENVIRONMENT_NAME} region: ap-northeast-2 iam-role: prod-ec2-iam-role -
둘째, HazelcastConfig.java
@EnableConfigurationProperties({HazelcastConfig.AwsConfig.class}) @Configuration public class HazelcastConfig { private final HazelcastServerConfigure configure; HazelcastConfig(final AwsConfig awsConfig, final Environment environment) { this.configure = new HazelcastServerConfigure(awsConfig, environment); } @Bean Config config() { return configure.toConfig(); } @Setter @Getter @ConfigurationProperties(prefix = "hazelcast.cluster.aws") static class AwsConfig { public static final String ELASTIC_BEANSTALK_ENVIRONMENT_NAME_KEY = "elasticbeanstalk:environment-name"; private String environmentName; private String region; private String iamRole; } } -
셋째, HazelcastServerConfigure.java
final class HazelcastServerConfigure { private static final Set<String> AWS_PROFILES = Sets.newHashSet("dev", "qa", "stage", "live"); private final HazelcastConfig.AwsConfig awsConfig; private final Environment environment; private final Config config; HazelcastServerConfigure(final HazelcastConfig.AwsConfig awsConfig, final Environment environment) { this.awsConfig = awsConfig; this.environment = environment; this.config = new Config(); } private void setPropertyConfig() { config.setProperty(ClusterProperty.CACHE_INVALIDATION_MESSAGE_BATCH_ENABLED.getName(), "false"); } private void setClusterNameConfig() { config.setClusterName(awsConfig.getEnvironmentName()); } private void setInstanceNameConfig() { config.setInstanceName(awsConfig.getEnvironmentName()); } private void setJoinConfig() { if (isAws()) { config.setNetworkConfig(new NetworkConfig() .setJoin(new JoinConfig() .setMulticastConfig(new MulticastConfig().setEnabled(false)) .setTcpIpConfig(new TcpIpConfig().setEnabled(false)) .setAwsConfig(new AwsConfig() .setEnabled(true) .setUsePublicIp(false) .setProperty("region", awsConfig.getRegion()) .setProperty("tag-key", ELASTIC_BEANSTALK_ENVIRONMENT_NAME_KEY) .setProperty("tag-value", awsConfig.getEnvironmentName()) .setProperty("iam-role", awsConfig.getIamRole()) .setProperty("hz-port", "5701-5701") ) ) ); } } private void setPartitionGroupConfig() { if (isAws()) { config.setPartitionGroupConfig(new PartitionGroupConfig() .setEnabled(true) .setGroupType(PartitionGroupConfig.MemberGroupType.ZONE_AWARE) ); } } private void setCacheConfig() { config.setMapConfigs(ImmutableMap.of("*", new MapConfig() .setStatisticsEnabled(true) .setInMemoryFormat(InMemoryFormat.BINARY) .setBackupCount(0) .setAsyncBackupCount(2) .setMaxIdleSeconds(21600) .setTimeToLiveSeconds(86400) .setEvictionConfig(new EvictionConfig() .setEvictionPolicy(EvictionPolicy.LRU) .setMaxSizePolicy(MaxSizePolicy.FREE_HEAP_PERCENTAGE) .setSize(50) ))); } private void setLockConfig() { config.setCPSubsystemConfig(new CPSubsystemConfig() .setLockConfigs(ImmutableMap.of("*", new FencedLockConfig() .disableReentrancy())) ); } private void setMetricsConfig() { config.setMetricsConfig(new MetricsConfig() .setEnabled(true) .setJmxConfig(new MetricsJmxConfig().setEnabled(true)) .setManagementCenterConfig(new MetricsManagementCenterConfig().setEnabled(false)) ); } private void setConfigPatternMatcherConfig() { config.setConfigPatternMatcher(new WildcardConfigPatternMatcher()); } public Config toConfig() { setPropertyConfig(); setInstanceNameConfig(); setClusterNameConfig(); setJoinConfig(); setPartitionGroupConfig(); setCacheConfig(); setLockConfig(); setMetricsConfig(); setConfigPatternMatcherConfig(); return config; } private boolean isAws() { final Set<String> activeProfiles = Arrays.stream(environment.getActiveProfiles()).collect(Collectors.toSet()); return activeProfiles.stream().anyMatch(AWS_PROFILES::contains); } }
모니터링
- Grafana
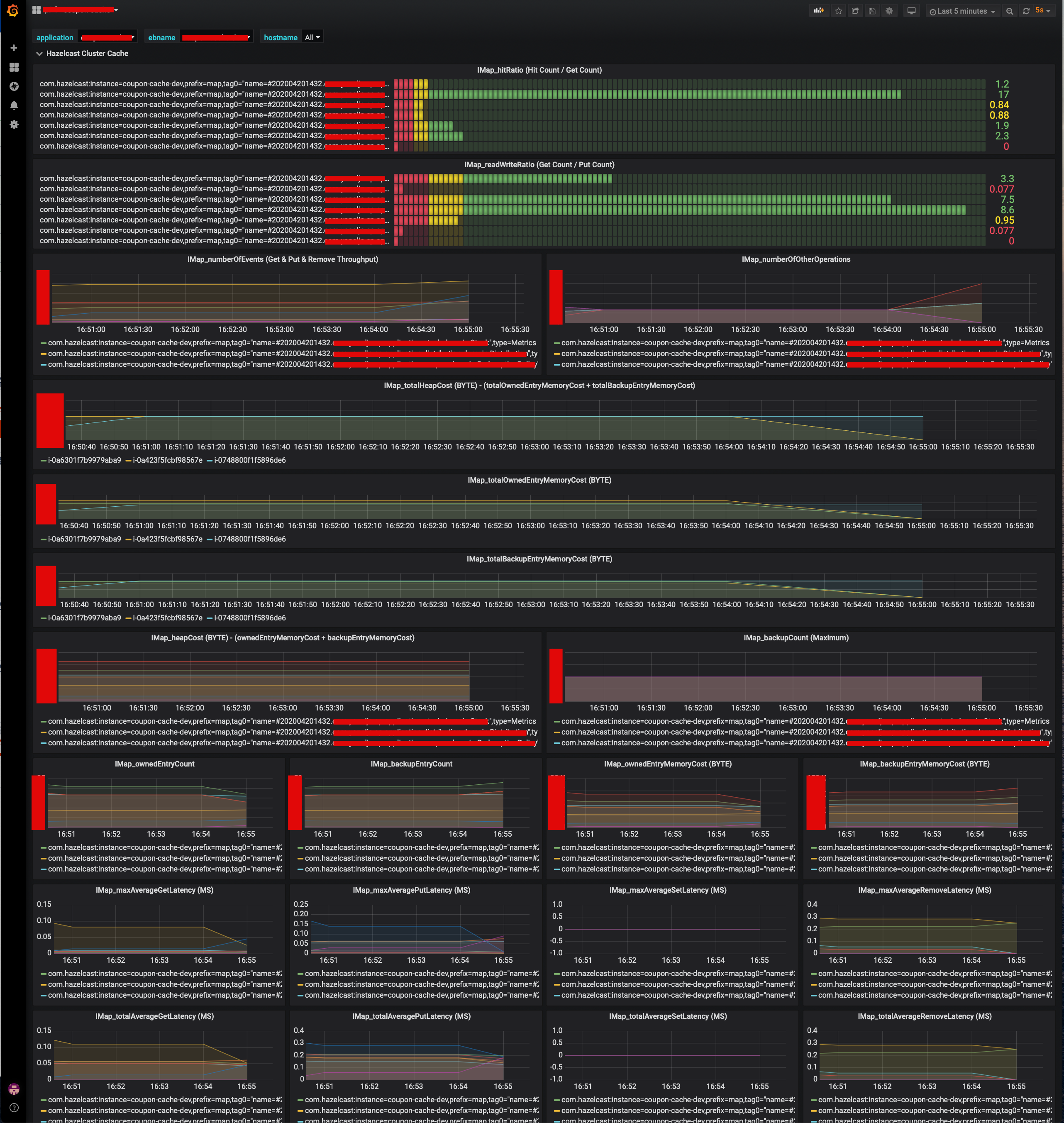
모니터링 지표 수집
- Micrometer
- Spring Boot2에서 정식 지원하는 Micrometer 프로젝트를 활용하여 지표 가공 및 수집
- 요구사항
- Spring은 Bean으로 등록할때 지표 수집 구현체들을 한번만 등록한다.
- 따라서, Runtime에 Client로부터 Cache Cluster에 신규 Cache가 추가되면, 추가 가능해야 한다.
-
어떻게 모니터링 지표 수집을 구현하는가 ?
-
첫째, HazelcastIMapMetricsRegistry
- Scheduler를 통해 일정 시간 간격으로, 지표를 추가 및 삭제한다.
- MultiGauge 기반 - 동일한 Name 기반으로 기존에 등록된 지표 삭제 및 새로 등록 가능.
@Component public class HazelcastIMapMetricsRegistry { private static final String OBJECT_NAME_PATTERN = "com.hazelcast:type=Metrics,instance=*,prefix=map,*"; private final MeterRegistry registry; private final HazelcastIMapMetrics hazelcastIMapMetrics; HazelcastIMapMetricsRegistry(final MeterRegistry registry) { this.registry = registry; this.hazelcastIMapMetrics = new HazelcastIMapMetrics(OBJECT_NAME_PATTERN, Collections.emptyList()); } @Scheduled(fixedDelay = 60000L) void register() { hazelcastIMapMetrics.bindTo(registry); } } -
둘째, HazelcastIMapMetrics
- MBean 으로 등록된 Hazelcast Metric을 읽어, Micrometer를 기반으로 등록한다.
@NonNullApi @NonNullFields public class HazelcastIMapMetrics extends MBeanMetrics { private final Map<String, MultiGauge> multiGaugeMap; public static void monitor(MeterRegistry registry, String objectName, String... tags) { monitor(registry, objectName, Tags.of(tags)); } public static void monitor(MeterRegistry registry, String objectName, Iterable<Tag> tags) { new HazelcastIMapMetrics(objectName, tags).bindTo(registry); } public HazelcastIMapMetrics(String objectNamePattern, Iterable<Tag> tags) { super(objectNamePattern, tags); this.multiGaugeMap = new ConcurrentHashMap<>(); } @Override protected void bindImplementationSpecificMetrics(MeterRegistry registry) { register(registry, "ownedEntryCount"); register(registry, "backupEntryCount"); register(registry, "backupCount"); register(registry, "ownedEntryMemoryCost"); register(registry, "backupEntryMemoryCost"); register(registry, "heapCost"); register(registry, "numberOfEvents"); register(registry, "numberOfOtherOperations"); customRegister(registry, "hitRatio", "hits", "getCount"); customRegister(registry, "readWriteRatio", "getCount", "putCount"); customRegister(registry, "totalMaxAverageGetLatency", "totalMaxGetLatency", "getCount"); customRegister(registry, "totalMaxAveragePutLatency", "totalMaxPutLatency", "putCount"); customRegister(registry, "totalMaxAverageSetLatency", "totalMaxSetLatency", "setCount"); customRegister(registry, "totalMaxAverageRemoveLatency", "totalMaxRemoveLatency", "removeCount"); customRegister(registry, "totalAverageGetLatency", "totalGetLatency", "getCount"); customRegister(registry, "totalAveragePutLatency", "totalPutLatency", "putCount"); customRegister(registry, "totalAverageSetLatency", "totalSetLatency", "setCount"); customRegister(registry, "totalAverageRemoveLatency", "totalRemoveLatency", "removeCount"); } private void register(MeterRegistry registry, String attributeName) { final String gaugeName = generateGaugeName(attributeName); final MultiGauge multiGauge = multiGaugeMap.computeIfAbsent(gaugeName, (name) -> MultiGauge.builder(name).register(registry)); multiGauge.register(lookupObjectNames() .stream() .map(objectName -> MultiGauge.Row.of(Tags.of(getTagsWithCacheName()).and(gaugeName, objectName.getCanonicalName()), () -> getDoubleValueSafety(() -> lookupStatistic(objectName, attributeName)))) .collect(Collectors.toList()), true); } private void customRegister(MeterRegistry registry, String customAttributeName, String firstAttributeName, String secondAttributeName) { final String gaugeName = generateGaugeName(customAttributeName); final MultiGauge multiGauge = multiGaugeMap.computeIfAbsent(gaugeName, (name) -> MultiGauge.builder(name).register(registry)); multiGauge.register(lookupObjectNames() .stream() .map(objectName -> MultiGauge.Row.of(Tags.of(getTagsWithCacheName()).and(gaugeName, objectName.getCanonicalName()), () -> getDoubleValueSafety(() -> lookupStatistic(objectName, firstAttributeName).doubleValue() / lookupStatistic(objectName, secondAttributeName)))) .collect(Collectors.toList()), true); } private static String generateGaugeName(String attributeName) { return "IMap.".concat(attributeName); } private double getDoubleValueSafety(DoubleSupplier doubleSupplier) { final double value = doubleSupplier.getAsDouble(); if (Double.isNaN(value) || Double.isInfinite(value)) return 0.0D; return value; } } -
셋째, HazelcastMBeanMetrics
- MBean 기반으로 등록된 Hazelcast Metric 수집 추상 클래스.
@NonNullApi @NonNullFields public abstract class MBeanMetrics implements MeterBinder { private final ObjectName objectNamePattern; private final Iterable<Tag> tags; public MBeanMetrics(String objectNamePattern, Iterable<Tag> tags) { try { this.objectNamePattern = new ObjectName(objectNamePattern); } catch (MalformedObjectNameException ignored) { throw new InvalidConfigurationException("Object name '" + objectNamePattern + "' results in an invalid JMX name"); } this.tags = Tags.concat(tags); } @Override public final void bindTo(MeterRegistry registry) { bindImplementationSpecificMetrics(registry); } protected abstract void bindImplementationSpecificMetrics(MeterRegistry registry); protected Iterable<Tag> getTagsWithCacheName() { return tags; } protected Set<ObjectName> lookupObjectNames() { try { List<MBeanServer> mBeanServers = MBeanServerFactory.findMBeanServer(null); for (MBeanServer mBeanServer : mBeanServers) { try { return mBeanServer.queryNames(objectNamePattern, null); } catch (RuntimeOperationsException ex) { // did not find MBean, try the next server } } } catch (SecurityException ex) { throw new IllegalStateException(ex); } return Collections.emptySet(); } protected Long lookupStatistic(ObjectName objectName, String attributeName) { try { List<MBeanServer> mBeanServers = MBeanServerFactory.findMBeanServer(null); for (MBeanServer mBeanServer : mBeanServers) { try { return (Long) mBeanServer.getAttribute(objectName, attributeName); } catch (AttributeNotFoundException | InstanceNotFoundException ex) { // did not find MBean, try the next server } } } catch (MBeanException | ReflectionException ex) { throw new IllegalStateException(ex); } // didn't find the MBean in any servers return 0L; } }
-
Cache Cluster 확장에 대한 의사결정
- 아래의 항목에 대해, 데이터 기반으로 의사결정을 내릴 수 있다.
캐시 클러스터 확장 여부 (클러스터 인스턴스 개수 증가 여부)캐시 클러스터 인스턴스 스펙 업그레이드 여부
- 근거 지표
- Java Option
Java 실행 옵션에서 설정한 JVM Heap Size
- Grafana
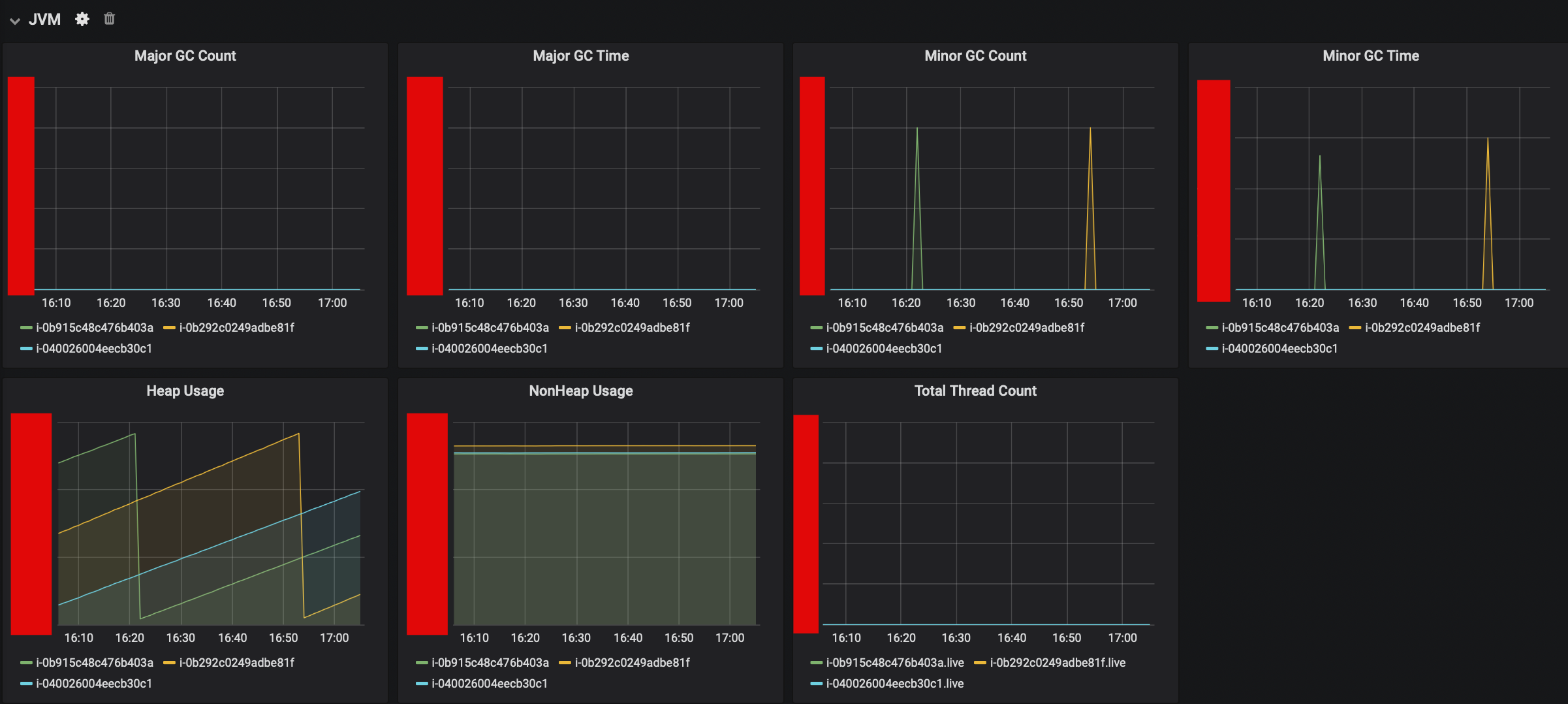
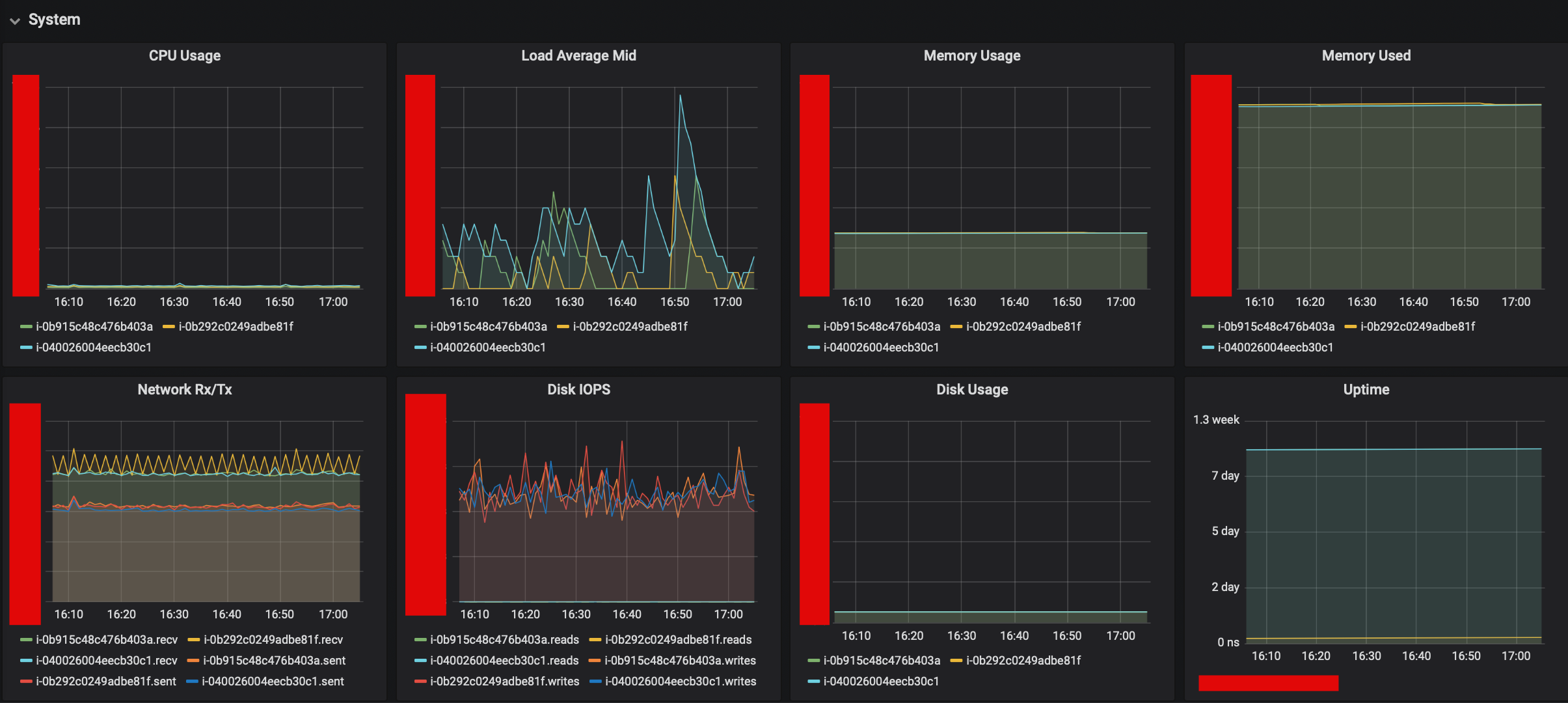
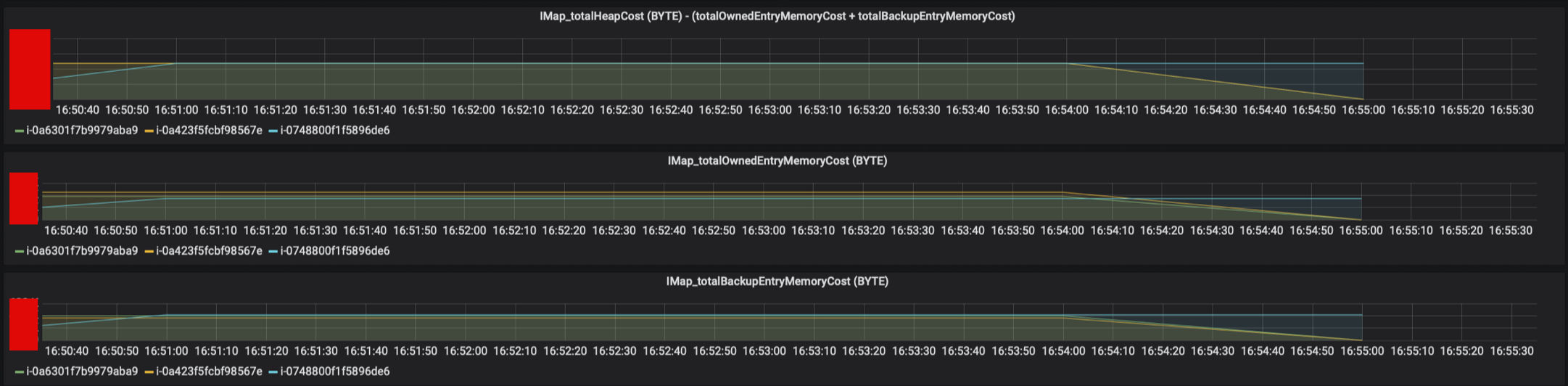
Minor & Major GC CountMinor & Major GC TimeHeap UsageSystem InformationIMap_totalHeapCost
- Java Option
- 근거 지표 상세
- Java Option
- Java 실행시 설정한 Heap -Xms, -Xmx 옵션 참고
- Grafana
- JVM
- System Information
- IMap_totalHeapCost
- JVM
- Java Option
- 의사결정
메모리 부족한가 ?- Java 실행 옵션으로 등록한 Heap Size가 4G라고 할 경우
- IMap_totalHeapCost는 각 인스턴스에 보관된 캐시의 Byte 사이즈를 표현합니다.
- 현재, Cache Eviction Algorithm은 LRU, MaxSizePolicy는 Free Heap Percentage 기준 50%로 설정되어 있습니다.
- 따라서, 4G의 50%인 2G를 넘어가지 않는 선에서 캐시로 사용된 메모리가 유지되어야, 불필요한 Eviction을 방지할 수 있습니다.
- 그 기준점에 가까울 경우, 메모리를 늘려야 한다는 판단을 할 수 있습니다.
- Java 실행 옵션으로 등록한 Heap Size가 4G라고 할 경우
컴퓨팅 파워가 부족한가 ?- 운영중인 AWS Instance Spec이 지원하는 최대 컴퓨팅 파워의 기준치에 가까울 경우 (T시리즈의 경우 각 타입마다 CPU 제한 수치가 다름)
- GC Count 혹은 GC Time이 비효율적으로 증가할 경우
- 위와 같은 케이스에서, 더 높은 스펙의 CPU를 보유한 인스턴스 타입으로 변경해야 한다는 판단을 할 수 있습니다.
- 운영중인 AWS Instance Spec이 지원하는 최대 컴퓨팅 파워의 기준치에 가까울 경우 (T시리즈의 경우 각 타입마다 CPU 제한 수치가 다름)
이상, Distributed Cache Cluster 개발편에서는
Hazelcast 특성은 무엇인지 ?
분산 시스템 이론과 Split Brain 현상에 대해 고려하였는지 ?
어떻게 분산 캐시 클러스터를 구축하는지 ?
어떻게 모니터링 지표를 수집하는지 ?
나아가 Cache Cluster 확장을 데이터에 근거해서 의사결정하는 방법까지 살펴보았습니다.