 pkgonan
pkgonan
주제
- Distributed Cache로 Hibernate Second Level Cache를 적용하여 성능 튜닝하기 - Second Level Cache 적용편
API 서버에 Second Level Cache 적용하기 위한 이론 정리
- 기본 개념
다양한 조회 패턴에서의 조합을 커버하기 위해, Result Cache가 아닌 Entity Cache. (DB Row 단위 Cache)
- Cache 적용 대상 도메인 추출 기준
- 첫째, 적용 대상은
반드시 Entity여야 한다. - 둘째, 대상
Entity의 성격이 Eventual Consistency 에 적합해야 한다. - 셋째, 해당 Entity의
Select/Update 비중이 Select가 더 많아야한다. - 넷째,
Cache Hit율이 높아야한다.
- 첫째, 적용 대상은
- Cache 적용 패턴
- Cache Aside
- Read Through
- Write Through
- Write Behind (Back)
- Cache 동작 방식
- 1차 Cache - Session Cache (Local)
- 2차 Cache - Near Cache (Local)
- 3차 Cache - Distributed Cache (Remote)
- 4차 DB - Database Access (Remote)
API 서버에 Second Level Cache 적용하기
-
첫째, 캐시를 적용할 Entity에 @Cacheable 적용
@Cacheable @Entity public class Entity implements Serializable { private static final long serialVersionUID = 1L; } -
둘째, application-{environment}.yml
spring: jpa: properties: hibernate.cache.use_second_level_cache: true hibernate.cache.use_query_cache: false hibernate.cache.use_minimal_puts: true hibernate.cache.use_reference_entries: true hibernate.cache.default_cache_concurrency_strategy: nonstrict-read-write hibernate.cache.region_prefix: ${BUILD_NAME} javax.persistence.sharedCache.mode: ENABLE_SELECTIVE hazelcast: cluster: aws: environment-name: ${EB_ENVIRONMENT_NAME} cluster-name: cache-cluster-live region: ap-northeast-2 iam-role: prod-ec2-iam-role -
셋째, HazelcastConfigAutoConfiguration.java (Config 설정을 통합 관리)
@Configuration public class HazelcastConfigAutoConfiguration { HazelcastConfigAutoConfiguration() {} @ConditionalOnProperty(prefix = "spring.jpa.properties", name = "hibernate.cache.use_second_level_cache", havingValue = "true") @EnableConfigurationProperties({HazelcastConfig.AwsConfig.class}) static class HazelcastConfig { private final HazelcastClientConfigure configure; HazelcastConfig(final HazelcastConfig.AwsConfig awsConfig, final Environment environment) { this.configure = new HazelcastClientConfigure(awsConfig, environment); } @Bean ClientConfig config() { return configure.toConfig(); } @Bean HazelcastInstance hazelcastInstance(final ClientConfig config) { return HazelcastClient.newHazelcastClient(config); } @Setter @Getter @ConfigurationProperties(prefix = "hazelcast.cluster.aws") static class AwsConfig { public static final String ELASTIC_BEANSTALK_ENVIRONMENT_NAME_KEY = "elasticbeanstalk:environment-name"; private String environmentName; private String clusterName; private String region; private String iamRole; } } } -
넷째, HazelcastClientConfigure.java (Cluster 접속 설정, Near Cache 설정, TTL, Max Idle Time 등)
final class HazelcastClientConfigure { private static final Set<String> AWS_PROFILES = Sets.newHashSet("dev", "qa", "stage", "live"); private final HazelcastConfig.AwsConfig awsConfig; private final Environment environment; private final ClientConfig config; HazelcastClientConfigure(final HazelcastConfig.AwsConfig awsConfig, final Environment environment) { this.awsConfig = awsConfig; this.environment = environment; this.config = new ClientConfig(); } private void setClusterNameConfig() { if (isAws()) { config.setClusterName(awsConfig.getClusterName()); } } private void setInstanceNameConfig() { config.setInstanceName(awsConfig.getEnvironmentName()); } private void setNetworkConfig() { if (isAws()) { config.setNetworkConfig(new ClientNetworkConfig() .setAwsConfig(new AwsConfig() .setEnabled(true) .setUsePublicIp(false) .setProperty("region", awsConfig.getRegion()) .setProperty("tag-key", ELASTIC_BEANSTALK_ENVIRONMENT_NAME_KEY) .setProperty("tag-value", awsConfig.getClusterName()) .setProperty("iam-role", awsConfig.getIamRole()) .setProperty("hz-port", "5701-5701") ) ); } } private void setNearCacheConfig() { config.setNearCacheConfigMap(ImmutableMap.of("*", new NearCacheConfig() .setTimeToLiveSeconds(3600) .setMaxIdleSeconds(600) .setInvalidateOnChange(true) .setInMemoryFormat(InMemoryFormat.OBJECT) .setEvictionConfig(new EvictionConfig() .setEvictionPolicy(EvictionPolicy.LRU) .setMaxSizePolicy(MaxSizePolicy.ENTRY_COUNT) .setSize(50000) ))); } private void setMetricsConfig() { config.setMetricsConfig(new ClientMetricsConfig() .setEnabled(true) .setJmxConfig(new MetricsJmxConfig().setEnabled(true)) ); } private void setConfigPatternMatcherConfig() { config.setConfigPatternMatcher(new WildcardConfigPatternMatcher()); } public ClientConfig toConfig() { setInstanceNameConfig(); setClusterNameConfig(); setNetworkConfig(); setNearCacheConfig(); setMetricsConfig(); setConfigPatternMatcherConfig(); return config; } private boolean isAws() { final Set<String> activeProfiles = Arrays.stream(environment.getActiveProfiles()).collect(Collectors.toSet()); return activeProfiles.stream().anyMatch(AWS_PROFILES::contains); } }
Second Level Cache 적용 취소 방법
- Cache Cluster와 연결되는 것을 원하지 않고, Second Level Cache를 Disable하여 순수 DB 조회를 하도록 원상복구 하려면 ?
- 설정 하나로 처리 가능하다.
-
application-{environment}.yml
* AS-IS hibernate.cache.use_second_level_cache: true * TO-BE hibernate.cache.use_second_level_cache: false
Second Level Cache 모니터링
- Grafana
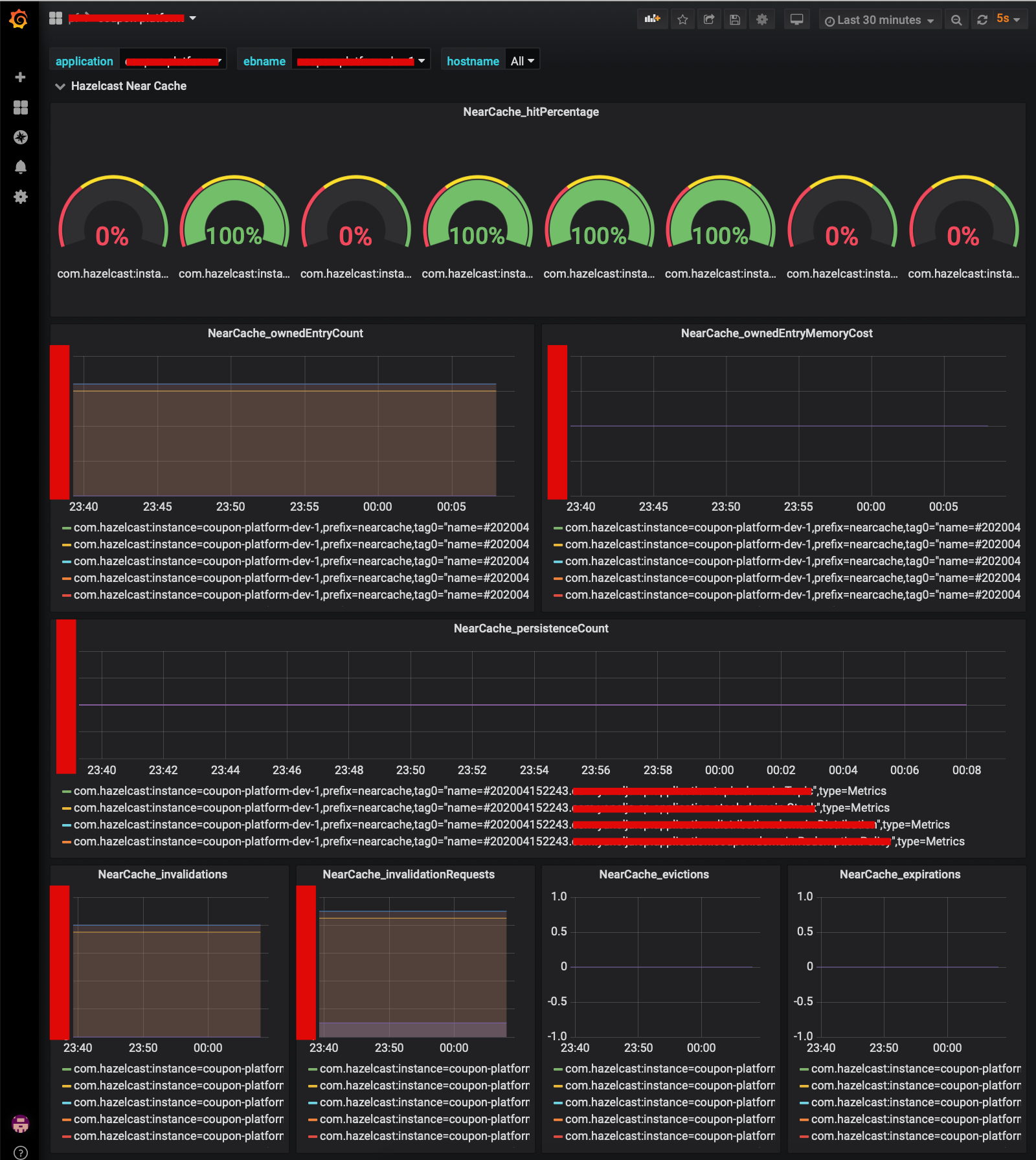
Second Level Cache 모니터링 지표 수집
- Distributed Cache Cluster 개발편의, 모니터링 지표 수집 항목 참고
- 동일한 패턴으로 구현하여 생략
Second Level Cache 튜닝
- 무엇을 튜닝하는가 ?
- 첫째, N개의 PK 조회를 Cache Hit 시킬 수 있는, Hibernate Multiload 활용하는 findAllByCachedId() 메소드 제공
- 둘째, 관리자 페이지 등 Cache를 타지 않아야 하는 경우를 위해 findByIdIgnoreCache() 메소드 제공.
-
코드 살펴보기
public interface CacheRepository<T, ID extends Serializable> { /** * findAllById Second Level Cache Hit 적용 * Second Level Cache에 존재하는 ID는 가져오고, 없는 ID들만 모아서 DB 조회 * * Flow * 1. Getting cache in Hibernate Session Cache (Local) * 2. Getting cache in Hazelcast Near Cache (Local) * 3. Getting cache in Distributed Cache (Remote) * 4. Getting entity in Database (Remote) **/ default List<T> findAllByCachedId(final Set<ID> ids) { if (ids.isEmpty()) { return Collections.emptyList(); } final Session session = getEntityManager().unwrap(Session.class); final MultiIdentifierLoadAccess<T> multiIdentifierLoadAccess = session.byMultipleIds(getClazz()) .enableReturnOfDeletedEntities(false) .enableOrderedReturn(false) .enableSessionCheck(true) .with(CacheMode.NORMAL) .with(LockOptions.NONE) .withBatchSize(100); return multiIdentifierLoadAccess.multiLoad(new ArrayList<>(ids)); } /** * findAllById Second Level Cache Ignore 적용 * 데이터를 가져올 때는 DB 참조 * 데이터를 가져온 후에는 Cache Update **/ default Optional<T> findByIdIgnoreCache(final ID id) { final Map<String, Object> properties = Maps.newHashMap(); properties.put("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS); properties.put("javax.persistence.cache.storeMode", CacheStoreMode.REFRESH); return Optional.ofNullable(getEntityManager().find(getClazz(), id, properties)); } EntityManager getEntityManager(); Class<T> getClazz(); }
Remote Cache의 Deserialization Problem의 해결
모든 Remote Cache는 Deserialization Issue가 발생할 수 있다.
일반적인 Cache 방식인 Custom Dto를 만들고 해당 Dto를 Caching을 하는 방식은 상대적으로 Deserialization Issue를 경험할 빈도가 적다. 해당 Dto의 Spec이 바뀌지 않으면 되기 때문이다.
Hibernate Second Level Cache를 사용할 경우, 내부적으로 Hibernate에서 정의한 Cache Key & Value Class로 Wrapping 해서 사용하므로 이를 쉽게 회피할 수 없다.
나아가, Entity의 Spec은 비지니스 요구사항에 따라 바뀔 수 있기에, Deserialization Issue를 경험할 빈도가 높다.
Second Level Cache를 활용하며, Deserialization 이슈를 회피하는 방법을 소개한다.
- 어떻게 해결하는가 ?
Build Version을 활용한 Application Versioning으로 해결- Jenkins를 통해 Build를 진행하며 각 Build시 $BUILD_DISPLAY_NAME 을 활용한다 (#20200501123)
- 시간이 흘러감에 따라 자동 증가, 개발자의 실수를 방지
- 만약, artifactVersion(ex - 1.0.0.RELEASE)을 활용할 경우 개발자가 버전을 변경하지 않는 실수 발생 가능
따라서, Build Version을 활용한다.
-
어떻게 구현하는가 ?
-
Jenkinsfile
- -PBUILD_NAME=$BUILD_DISPLAY_NAME 을 통해 BUILD_NAME을 주입
library identifier: 'yanolja-pipeline-library', changelog: false node { props = readProperties file: 'gradle.properties' artifactName = props['artifactName'] artifactVersion = props['artifactVersion'] } def meta = publishMeta( awsProfile: "${AWS_PROFILE}", yanoljaProfile: "${RELEASE_TARGET}", applicationName: "${artifactName}", environmentName: "${env.JOB_NAME}", targetFile: "build/${artifactName}-*.zip" ) publishAppPipeline meta: meta, timeoutMin: 60, { packageJava meta: meta, { sh 'export GRADLE_OPTS=-Xmx512m && bash gradlew -PBUILD_NAME=$BUILD_DISPLAY_NAME clean build zip --refresh-dependencies' } } -
build.gradle
- Build시 BUILD_NAME으로 File 생성
// Inject jenkins build name using file for second level cache versioning. task createExternalProperties(dependsOn: bootJar) { doLast { def JENKINS_BUILD_NAME = project.properties['BUILD_NAME'] ?: '' new File(projectDir, "external.properties").text = """BUILD_NAME=${JENKINS_BUILD_NAME}""" } } -
run.sh
- AWS Beanstalk 환경에서, Java Application 수행시 external.properties 파일을 읽어 BUILD_NAME을 Java 실행 Option에 추가.
#!/usr/bin/env bash ..... # Load Auto Increment Jenkins Build Name for Second Level Cache Versioning source external.properties echo ${BUILD_NAME} if [ -z "$BUILD_NAME" ]; then echo "JENKINS BUILD_NAME is unset or empty!" exit 1 fi JAVA_OPTS="$JAVA_OPTS -DBUILD_NAME=$BUILD_NAME" # Run Java exec java $JAVA_OPTS $var_jmx_opts -jar $EB_APP_NAME-*.jar -
application-{environment}.yml
- Versioning을 위해 hibernate.cache.region_prefix에 BUILD_NAME을 주입
spring: jpa: properties: hibernate.cache.use_second_level_cache: true hibernate.cache.use_query_cache: false hibernate.cache.use_minimal_puts: true hibernate.cache.use_reference_entries: true hibernate.cache.default_cache_concurrency_strategy: nonstrict-read-write hibernate.cache.region_prefix: ${BUILD_NAME} javax.persistence.sharedCache.mode: ENABLE_SELECTIVE
-
Remote Cache의 Deserialization Problem의 해결 방법은 이슈가 없는가 ?
Cache Bucket이 삭제되지 않아, 배포할때마다 Cache Bucket이 증가하는 이슈가 존재.- Cache Bucket의 Prefix를 통해 Versioning을 진행, 배포할때마다 여러개의 Cache Bucket이 생긴다.
- 삭제 대상의 Cache Bucket & Metric 을 인지하고 지속 삭제 필요.
Application Versioning으로 인한 Cache Bucket 증가 이슈는 어떻게 해결할까 ?
- 어떻게 동작하는가 ?
- Spring Create & Destroy Hook을 통해 각 Cache Map을 참조하는 Instance의 개수를 카운팅
- Spring Application Context가 올라오면, 참조하는 Map의 카운트를 증가
- Spring Application Context가 내려가면, 참조하는 Map의 카운트를 감소
- 개수가 0인 Map은 Cleansing 대상, Cache Cluster에 등록된 Cache Map 삭제
- Spring Create & Destroy Hook을 통해 각 Cache Map을 참조하는 Instance의 개수를 카운팅
-
동작 방식 예시
- Bucket Name
- 2020년 1월 1일에 배포를 했고, 새 버전을 2020년 2월 1일에 배포. Coupon 도메인만 예를 들어 설명.
- 기존 Cache Bucket Name : #20200101001.Coupon
- 신규 Cache Bucket Name : #20200201001.Coupon
- 2020년 1월 1일에 배포를 했고, 새 버전을 2020년 2월 1일에 배포. Coupon 도메인만 예를 들어 설명.
- 각 Bucket 별 Counter
- 기존 운영중인 인스턴스가 2대라고 가정.
- 신규 인스턴스 배포 전
- #20200101001.Coupon : 2
- 신규 인스턴스 배포 시작 (예시 : 인스턴스 추가를 통한 롤링 배포)
- Spring Create Hook - 현재 Map의 Counter 증가
- #20200101001.Coupon : 2
- #20200201001.Coupon : 1
- Spring Create Hook - 현재 Map의 Counter 증가
- 기존 인스턴스 한대 제거
- Spring Destroy Hook - 현재 Map의 Counter 감소 및 클렌징 시도 (Counter가 0이면 클렌징)
- #20200101001.Coupon : 1
- #20200201001.Coupon : 1
- Spring Destroy Hook - 현재 Map의 Counter 감소 및 클렌징 시도 (Counter가 0이면 클렌징)
- 신규 인스턴스 한대 추가
- Spring Create Hook - 현재 Map의 Counter 증가
- #20200101001.Coupon : 1
- #20200201001.Coupon : 2
- Spring Create Hook - 현재 Map의 Counter 증가
- 기존 인스턴스 한대 제거
- Spring Destroy Hook - 현재 Map의 Counter 감소 및 클렌징 시도 (Counter가 0이면 클렌징)
- #20200101001.Coupon : 0
- #20200201001.Coupon : 2
- Spring Destroy Hook - 현재 Map의 Counter 감소 및 클렌징 시도 (Counter가 0이면 클렌징)
- 배포 종료
- #20200201001.Coupon : 2
- 신규 인스턴스 배포 전
- 기존 운영중인 인스턴스가 2대라고 가정.
- Bucket Name
-
어떻게 구현하는가 ?
/** * Cache map cleansing service * Cache map name is auto increment key for versioning using jenkins build name (BUILD_NAME). * * @author Minkiu Kim */ @Slf4j @Component class CacheCleanService { private static final String CACHE_LOCK_KEY = "cache.lock"; private final SessionFactoryImplementor sessionFactoryImplementor; private final HazelcastInstance hazelcastInstance; CacheCleanService(final ObjectProvider<HazelcastInstance> hazelcastInstanceProvider, final ObjectProvider<EntityManagerFactory> entityManagerFactoryProvider) { this.hazelcastInstance = hazelcastInstanceProvider.getIfUnique(); final EntityManagerFactory entityManagerFactory = entityManagerFactoryProvider.getIfUnique(); this.sessionFactoryImplementor = Objects.nonNull(entityManagerFactory) ? entityManagerFactory.unwrap(SessionFactoryImplementor.class) : null; } /** * Increasing cache member count */ @PostConstruct void increaseCacheMember() { if (!isAvailable()) return; final FencedLock locker = getLock(CACHE_LOCK_KEY); if (!locker.tryLock(30L, TimeUnit.MINUTES)) { throw new LockAcquisitionException(); } try { executeInTransaction(createTransactionContext(), tx -> { doIncreaseCacheMember(tx); clearCache(); }); } finally { locker.unlock(); } } /** * Decreasing cache member count */ @PreDestroy void decreaseCacheMember() { if (!isAvailable()) return; final FencedLock locker = getLock(CACHE_LOCK_KEY); if (!locker.tryLock(30L, TimeUnit.MINUTES)) { throw new LockAcquisitionException(); } try { executeInTransaction(createTransactionContext(), this::doDecreaseCacheMember); executeInTransaction(createTransactionContext(), this::destroyCache); } finally { locker.unlock(); } } private TransactionContext createTransactionContext() { try { return hazelcastInstance.newTransactionContext(); } catch (Exception e) { log.error("[Exception] Create Transaction Context", e); throw e; } } private void executeInTransaction(final TransactionContext tx, final TransactionExecutor executor) { try { tx.beginTransaction(); executor.execute(tx); tx.commitTransaction(); } catch (Exception e) { tx.rollbackTransaction(); log.error("[Exception] Transaction Execution", e); throw e; } } @FunctionalInterface private interface TransactionExecutor { void execute(TransactionContext tx); } private void doIncreaseCacheMember(final TransactionContext tx) { for (String cacheName : getLocalCacheNames()) { TransactionalQueue<Object> queue = tx.getQueue(cacheName); queue.offer(1); log.info("[Increase] Cache Bucket : {}, Members : {}", cacheName, queue.size()); } } private void doDecreaseCacheMember(final TransactionContext tx) { for (String cacheName : getLocalCacheNames()) { TransactionalQueue<Object> queue = tx.getQueue(cacheName); queue.poll(); log.info("[Decrease] Cache Bucket : {}, Members : {}", cacheName, queue.size()); } } /** * Destroy cache which is zero member */ private void destroyCache(final TransactionContext tx) { for (String cacheName : getClusterCacheNames()) { final TransactionalQueue<Object> queue = tx.getQueue(cacheName); final int remainCacheMembers = queue.size(); if (0 == remainCacheMembers) { final TransactionalMap<Object, Object> map = tx.getMap(cacheName); map.destroy(); queue.destroy(); log.info("[Destroy] Cache Bucket : {}, Members : {}", cacheName, remainCacheMembers); } else if (0 > remainCacheMembers) { log.warn("[Destroy] Invalid remainCacheMember - Detected not atomic value. {}", remainCacheMembers); } } } /** * Clearing cache for eventual consistency * between previous cache buckets and next cache buckets while publishing new version. */ private void clearCache() { for (String cacheName : getLocalCacheNames()) { getCache(cacheName).clear(); log.info("[Clear] Cache Bucket : {}", cacheName); } } private FencedLock getLock(final String name) { return hazelcastInstance.getCPSubsystem().getLock(name); } private IMap<?, ?> getCache(final String name) { return hazelcastInstance.getMap(name); } private List<String> getClusterCacheNames() { return hazelcastInstance.getDistributedObjects().stream() .filter(distributedObject -> QueueService.SERVICE_NAME.equals(distributedObject.getServiceName())) .map(DistributedObject::getName) .collect(Collectors.toList()); } private List<String> getLocalCacheNames() { final SessionFactoryOptions sessionFactoryOptions = sessionFactoryImplementor.getSessionFactoryOptions(); final String cacheRegionPrefix = sessionFactoryOptions.getCacheRegionPrefix(); return sessionFactoryImplementor.getCache() .getCacheRegionNames() .stream() .map(cacheRegionName -> StringHelper.qualifyConditionally(cacheRegionPrefix, cacheRegionName)) .collect(Collectors.toList()); } private static class LockAcquisitionException extends RuntimeException { } private boolean isAvailable() { return Objects.nonNull(hazelcastInstance) && Objects.nonNull(sessionFactoryImplementor); } } -
배포 중 발생하는, 신규 Version과 구 Version의 불일치 문제는 없는가 ?
- 상황
- 신규 버전 Rolling으로 배포 중, 기존 버전 = V1, 신규 버전은 V2라고 가정
- 배포 중에 Entity Update 요청이 V1으로 오게 되면 V2는 이를 알 수 없다.
- 아이디어
- Spring Hook을 통해 Create Hook을 받아 캐시 Clear
- Spring Instance가 새로 뜨게되면 현재 바라보고 있는 Cache를 Clear하여 불일치를 해결
- Spring Hook을 통해 Create Hook을 받아 캐시 Clear
- 아이디어의 구현
- 위에서 기술한 Cache Bucket 증가 이슈의 clearCache() 코드 참조.
- 상황
적용 결과
- Performance
- 쿠폰함 조회 API
약 3배의 성능 개선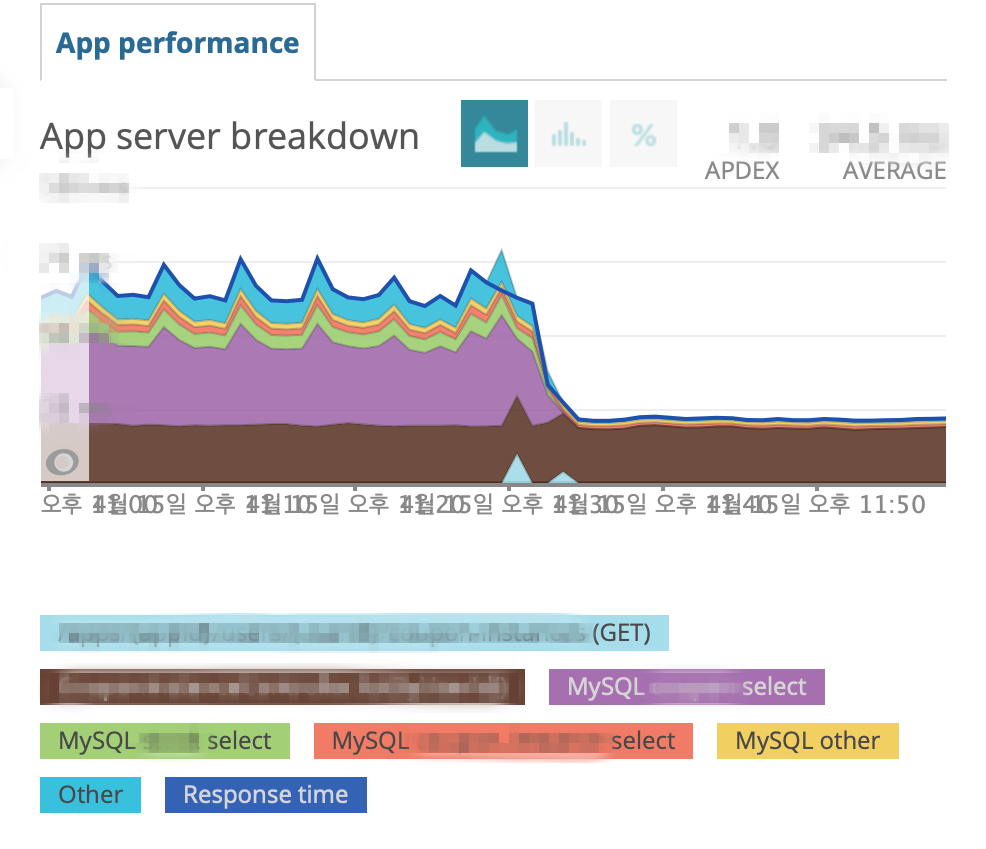
- 쿠폰함 조회 API
- DB I/O
- 쿠폰함 조회 API
API 요청 1번당, Select 5건 -> Select 1건 개선
Before After 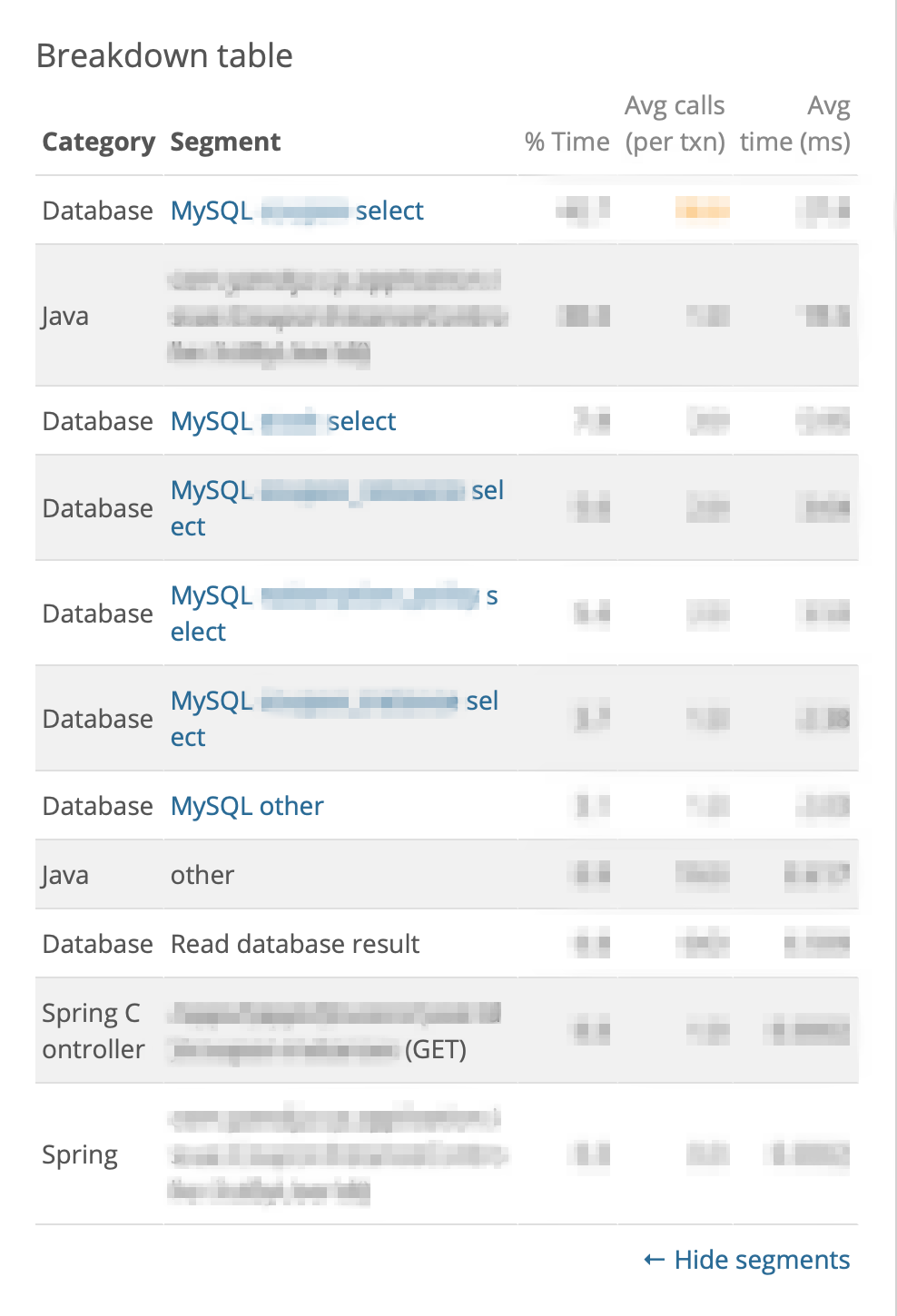
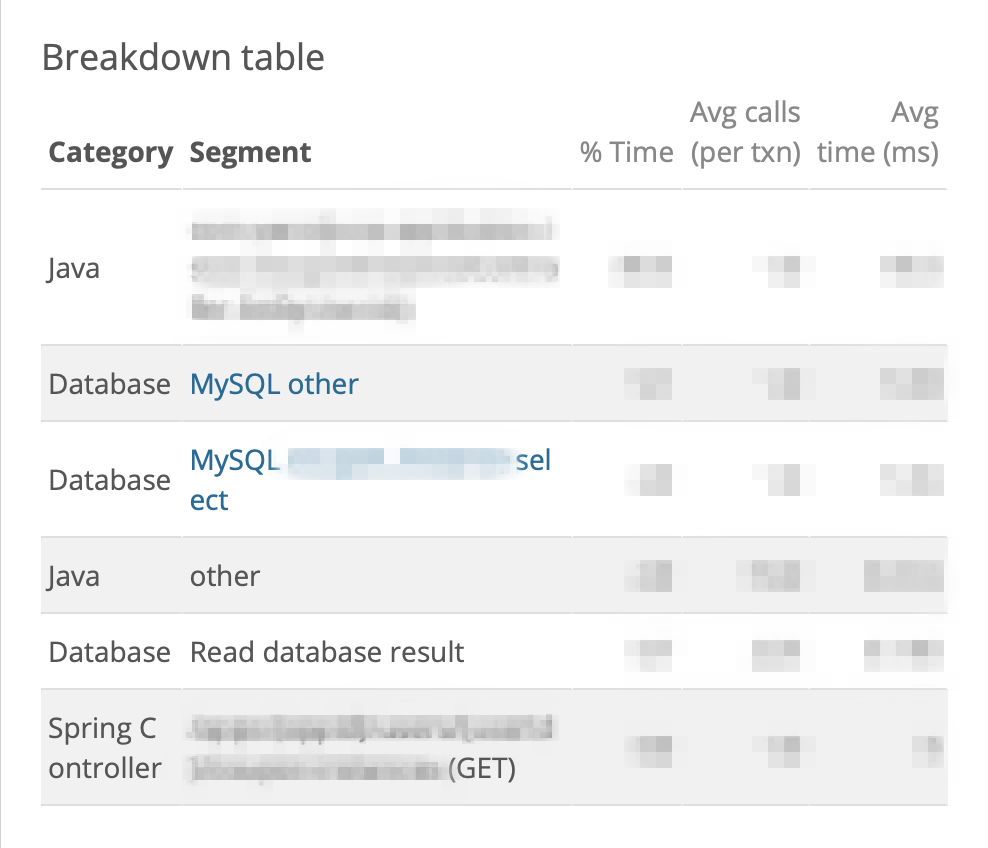
- 쿠폰함 조회 API
- Throughput
- 쿠폰함 조회 API
Throughput 3배 증가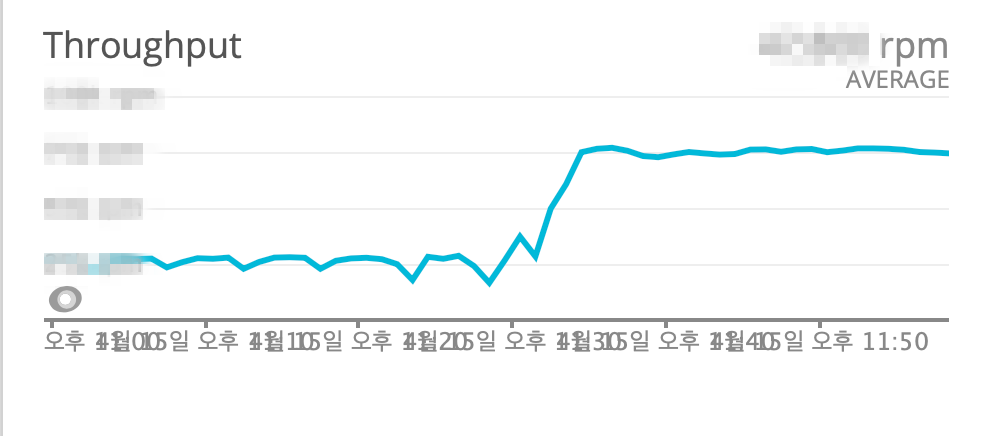
- 쿠폰함 조회 API
- Ngrinder 부하 테스트
- 쿠폰함 조회 API
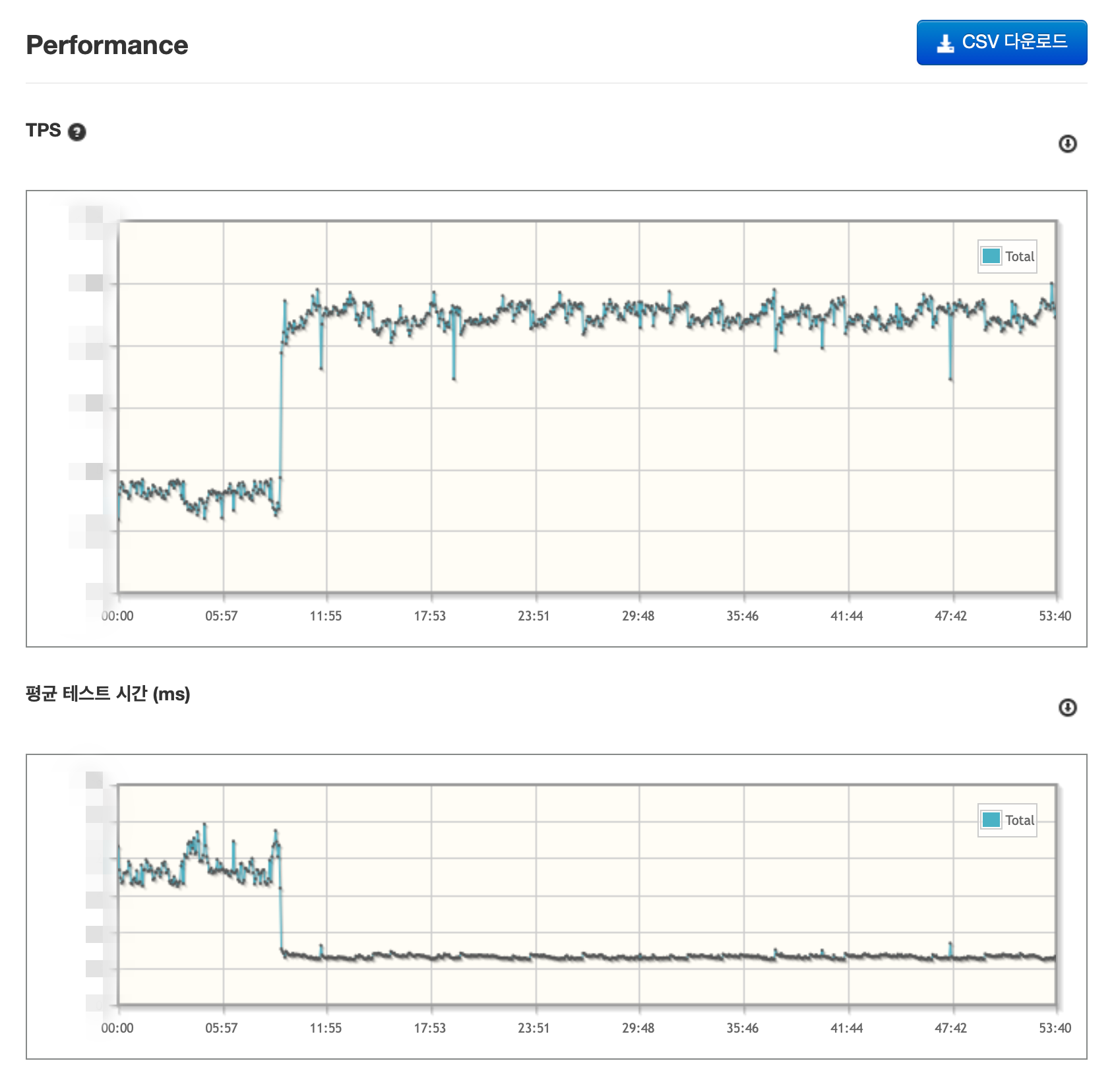
- 쿠폰함 조회 API
이상, Second Level Cache 적용편에서는
어떤 Entity에 캐시를 적용해야 하는지 ?
Cache 적용 패턴과 동작 방식은 무엇인지 ?
Remote Cache의 Deserialization Issue를 해결하기 위한 기법은 무엇인지 ?
나아가 Near Cache를 활용하여 Second Level Cache를 적용하는 방법과, 그 결과까지 살펴보았습니다.
마지막 3편을 끝으로, Distributed Cache로 Hibernate Second Level Cache를 적용하여 성능 튜닝하기 시리즈를 마칩니다.